Imaging Place using Generative Adversarial Networks
Kyle Steinfeld
This project applies techniques in machine learning,
specifically generative adversarial networks (or GANs),
to produce synthetic images
intended to capture
the predominant visual properties
of urban places.
We propose that imaging cities in this manner
represents the first data-driven approach
to documenting the *Genius Loci* of a city,
which is understood to include
those forms,
textures,
colors,
and qualities of light
that exemplify a particular urban location
and that set it apart
from similar places.
This project applies techniques in machine learning, specifically generative adversarial networks (or GANs), to produce synthetic images intended to capture the predominant visual properties of urban places. We propose that imaging cities in this manner represents the first computational approach to documenting the Genius Loci of a city ( Norberg-Schulz, 1980 ), which is understood to include those forms, textures, colors, and qualities of light that exemplify a particular urban location and that set it apart from similar places.
I'll present today
methods for the collection
of urban image data,
for the necessary processing
and formatting of this data,
and for the training
of two known computational statistical models
that identify visual patterns
distinct to a given site
and that reproduce these patterns
to generate new images.
These methods have been applied
to image nine distinct urban contexts
across six cities
in the US and Europe.
While the product of this work
is not a tool for the design of cities
or the design of building forms,
but rather a method
for the synthetic imaging
of existing places,
we nevertheless seek
to situate the work
in terms of computer-assisted design (CAD).
In this regard,
the project is demonstrative of
an alternative approach to CAD tools.
In contrast with existing parametic tools
that seek to capture
the explicit intention of their user,
in applying computational statistical methods
to the production of images
that speak to the implicit qualities
that constitute a place,
this project demonstrates
the unique advantages
offered by such methods
in *capturing and expressing the tacit*.
Presented here are methods for the collection of urban image data, for the necessary processing and formatting of this data, and for the training of two known computational statistical models (StyleGAN ( Karras et al., 2018 ) and Pix2Pix ( Isola et al., 2016 ) ) that identify visual patterns distinct to a given site and that reproduce these patterns to generate new images. These methods have been applied to image nine distinct urban contexts across six cities in the US and Europe, the results of which are presented here. While the product of this work is not a tool for the design of cities or building forms, but rather a method for the synthetic imaging of existing places, we nevertheless seek to situate the work in terms of computer-assisted design (CAD). In this regard, the project is demonstrative of a new approach to CAD tools. In contrast with existing tools that seek to capture the explicit intention of their user ( Aish, Glynn, Sheil 2017 ), in applying computational statistical methods to the production of images that speak to the implicit qualities that constitute a place, this project demonstrates the unique advantages offered by such methods in capturing and expressing the tacit.
Background
I'm sure I don't need to mention
that this concept of Genius Loci
comes to us from Christian Norberg-Schulz.
Motivation
In digital architectural design, since the introduction of parametric modeling techniques, the "integration of design intent into computational models" ( Kilian, 2014 129 ) has remained one of the largest unmet challenges, and represents the most glaring unmet promise of computation as a partner in creative design ( Steinfeld, 2017 ). While, in contrast with non-associative CAD modeling, the stated ambition of parametric design software is the capturing of the explicit intention of the designer ( Aish, Glynn, Sheil 2017 ), this ambition has been successfully met in only a narrow subset of cases: those in which the designer is able to explicitly articulate their intention. For many designers, however, design intent is a necessarily tacit concept, a prevalent attitude that is nevertheless largely unsupported by contemporary CAD tools. This project represents a small step toward a new approach to CAD tools that addresses this unmet need, and that is configured to better support tacit or difficult-to-articulate design intent.
To clearly demonstrate the needs of tacit design intent, this project considers a scenario that offers an especially difficult to explicitly articulate intent. Here we imagine a set of digital tools for architectural phenomenologists. In particular, we have in mind a movement of post-modern Italian movement called "La Tendenza", which included architects such as Vittorio Gregotti and Aldo Rossi.
In his seminal work that defines a phenomenological approach, "Genius Loci: Towards a Phenomenology of Architecture", Christian Norberg-Schulz argues that the design of cities and buildings must center on the construction of "place", which he defines as a "space with a unique character" ( Norberg-Schulz, 1980 94). But how is this "unique character" defined, and how can it be captured using digital tools in manner that affords the advantages of a computational medium? This project seeks just this. In anticipation of a future tool that better supports the development of tacit design intent, we seek to leverage methods in machine learning to attempt to encode Norberg-Schulz's concept of "place".
Who,
in his seminal work published in 1980
argues that the design of cities and buildings
must center on the construction of "place",
which he defines as
a "space with a unique character"
"When a town pleases us
because of its distinct character,
it is usually because
a majority of its buildings
are related to the earth and the sky
in the same way;
they seem to express a common form of life,
a common way of being on the earth.
Thus they constitute a genius loci
which allows for human identification."
He writes:
"When a town pleases us
because of its distinct character,
it is usually because
a majority of its buildings
are related to the earth and the sky
in the same way;
they seem to express a common form of life,
a common way of being on the earth.
Thus they constitute a genius loci
which allows for human identification."
This idea
"placefulness"
is at odds
with our typical understanding
of the digtial.
In fact, there are advocates of the digital
who have spoken directly against this idea.
In his 1995 book "Being Digital",
Nicholas Negroponte,
founder of the the Media Lab
has been in the news a bit lately,
Negroponte sought to further
what we might now understand with some remorse
as a "march toward placelessness"
that is associated with technologies
of easily-accessible remote sensing (like google maps)
and omniprecent telepresecnce (like facetime).
Writing in 1995, Negroponte asserted that
Place doen't matter
"eventually,
even the transmission of place
would become possible"
"In the same ways that hypertext
removes the limitations of the printed page,
the post-information age
will remove the limitations of geography.
Digital living will include
less and less dependence upon
being in specific place at specific time,
and the transmission of place itself
will start to become possible."
One way to position this work
is as a speculation:
What would Norberg-Schulz do
with the tools of Negroponte?
Another way to position this work
as described in more detail in our paper,
is as fulfilling an unmet promise
of computational design:
some of the first
to develop parametric modeling tools
for architectural designers
described the their ambition
that these tools "capture the design intent"
of their users.
this hasn't panned out,
because
parametric models are explicit descriptions,
while "design intent" is a necessarily tacit concept.
Technical Background
ML is an approach to AI
that does not require people
to explicitly program computers,
but rather to "train" them
on existing data,
it is especially well-suited
for programming tasks
that are too large or complex
to accomplish "by hand".
It is for this reason
we hypothesize that ML techniques
might hold relevance
in supporting *tacit design intent*.
It is the ambition of this project
to use a GAN as a tool for tacit design,
and to apply the capacity of this technology
for capturing the implicit visual properties
of a set of images.
We speculate that this capacity
will prove useful
in uncovering and encoding
a phenomenological understanding of place.
Recent advances in computational statistical classification, specifically in machine learning (ML), have demonstrated applicability to a range of disciplines and domains. Machine learning is an approach to artificial intelligence (AI) that employs statistical processes of knowledge discovery. This approach may be broadly understood as "learning through observation", in which patterns of data are discovered and may be mapped onto other patterns without direct human intervention ( Bechtel & Abrahamsen, 2002 ). In contrast with other approaches, ML does not define chains of reasoning or heuristic logics in advance, but rather seeks to discover patterns through statistical methods. Since this approach to artificial intelligence does not require people to explicitly program computers, but rather to "train" them on existing data, it is especially well-suited for programming tasks that are too large or complex to accomplish "by hand". It is for this reason we hypothesize that ML techniques might hold relevance in supporting tacit design intent. It is for this same reason that large sets of relevant and well-formed data are required.
The architecture engineering and construction (AEC) industry has broadly recognized the success of ML in other domains, and has recently sought to apply these techniques to architectural and urban design. Given the requirement for large datasets, it is natural that these initial applications are often related to easily-accessed preexisting sources of data; such as climate data at the regional scale, geographic information system (GIS) data at the urban scale, and simulation data or building information models (BIM) at the building scale. In our reliance on an existing dataset of images of cities (Google StreetView), this project is no exception in this regard, but is distinct from another perspective. The preponderance of early applications of ML to AEC have been analytical in nature. For example, approaches have been recently developed for monitoring air pollution in cities ( Chung and Jeng, 2018 ), for the automation of construction using irregular building materials ( Cheng and Hou, 2016 ), and for the classification of spatial types using isovists ( Peng, 2017 ). These examples demonstrate the applicability of statistical classification and regression to architectural analysis. While improved analytical methods certainly hold value, since design is fundamentally about creative production, we see a greater untapped potential in a model of ML that is currently under-recognized the AEC industry: the generative model.
Returning again to the state of the art in ML, broadly speaking, there are currently two distinct approaches: discriminative models and generative models ( Ng, Jordan 2001 ). The distinction between these holds relevance for their application to architecture and urban design: where discriminative models attempt learn the boundary between discovered classes of data, generative models learn the rules by which new members of these classes may be produced. Where a discriminative model holds value for classification and regression tasks, a generative model is able to produce entirely new instances of discovered patterns of data. This capacity of generative models explains the recent enthusiasm in creative circles for a particular class of generative model described as a "generative adversarial network", or GAN.
First proposed by Ian Goodfellow ( Goodfellow et al., 2014 ), a GAN instrumentalizes the adversarial relationship between two neural networks: one network tasked with generating synthetic images able to "pass" for those drawn from a given set, and a second network designed to discern real from fake. The result of a successfully trained GAN model is a program that is capable of convincingly producing new synthetic images that exhibit traits that resemble those exhibited by a set of given images. The body of new synthetic images is understood as a "latent space" of images, and is typically described as a high-dimensional parametric design space. It is noteworthy that these traits need not be made explicit in advance. Rather, they are implied by the qualities of the data provided, and are discovered during the process of training. GANs have enjoyed much attention lately for their ability to generate visual material, and have even found application in the visual arts .
It is the ambition of this project to use a GAN as a tool for tacit design, and to apply the capacity of this technology for capturing the implicit yet salient visual properties of a set of images. We speculate that this capacity will prove useful in uncovering and encoding a phenomenological understanding of place.
Methods
I'll now describe the steps required
to train a GAN
to produce images
that capture the predominant visual properties
of an urban context.
The work proceeds in three stages:
data preparation,
model training, a
and latent space exploration.
Here we describe the steps required to train a generative adversarial network (GAN) to produce images that capture the predominant visual properties of an urban context. The work proceeds in three stages: data preparation, model training, and latent space exploration.
In the data preparation stage, we first collect, clean, and curate a large number of images related to a selection of urban contexts, and compile these into distinct sets. Then, each set of these images is processed to serve as training data for one of two ML models. In support of these steps, presented here is an overview of the functions required and interfaces employed for collecting, curating, and processing panoramic images using Google's StreetView API. In this scope of work, these functions are expressed as a number of related libraries in Python, and the code made available at the repository location related to this text.
In the model training stage, we use the collected image sets to train GAN models capable of generating new images related to each selected urban context. To this end, two distinct GAN architectures are employed: StyleGAN and Pix2Pix, the particular implementations of which are discussed below. Once trained, each of these models prove valuable in their own way, as each offers a distinct interface for the production of synthetic urban images.
Finally, in the image generation stage, we develop methods for interfacing with the trained models in useful ways. This task is non-trivial, since each GAN model, once trained, is capable of producing a vast and overwhelming volume of synthetic images, which is described in terms of a high-dimensional latent space. The StyleGAN model offers a unique form of guiding the generation of images as combinations of features drawn from other images selected from latent space. The Pix2Pix model offers quite a different interface, with new synthetic images generated as transformations of arbitrary given source images: in our case, these are depth-maps of urban spaces.
Data Preparation
As is true with any computational statistical technique which relies on the discovery of patterns in existing data, the effective preparation of training data sets is essential to the training of generative adversarial networks. A GAN is only as good as the data it was trained on. As such, a bulk of the work required by this project is related to the collection, curation, and processing of images of urban places in preparation for training.
This section details this process, which includes: tasks related to the identification of a desired geographic location, the collection of a large and diverse set of images from this location, the curation of this set to define a relevant sub-set of valid images, and finally, the processing of these images such that they are appropriately formatted for training. Practically speaking, the project relies heavily on images drawn from the Google StreetView API, along with a Python library custom-written to collect images from this service and to handle the requisite curation and processing tasks. The functions mentioned in the sections below are integrated into this Python library, which has been made available at the repository location related to this text.
In this scope of work, following the procedures described below, data from nine urban sites is compiled for training, as described in the following table.
@[](table_of_places.png){}
Urban Place
Coordinates (Lat/Lng)
Blijdorp, Rotterdam, NL
51.927380, 4.466203
Pickwick Park, Jacksonville, FL
30.207098, -81.627929
Williamsburg, Brooklyn, NY
40.715607, -73.948484
East Campus, Gainesville, FL
29.649282, -82.335609
Alamo Square, San Francisco, CA
37.775383, -122.432817
Adams Point, Oakland, CA
37.810573, -122.254269
Central Square, Cambridge, MA
42.365222, -71.096106
Clark Kerr, Berkeley, CA
37.861839, -122.251198
Bushwick, Brooklyn, NY
40.705412, -73.920998
In the data preparation stage,
we first
collect, clean, and curate
a large number of images
related to a selection of urban contexts,
and compile these into distinct sets.
Data Collection
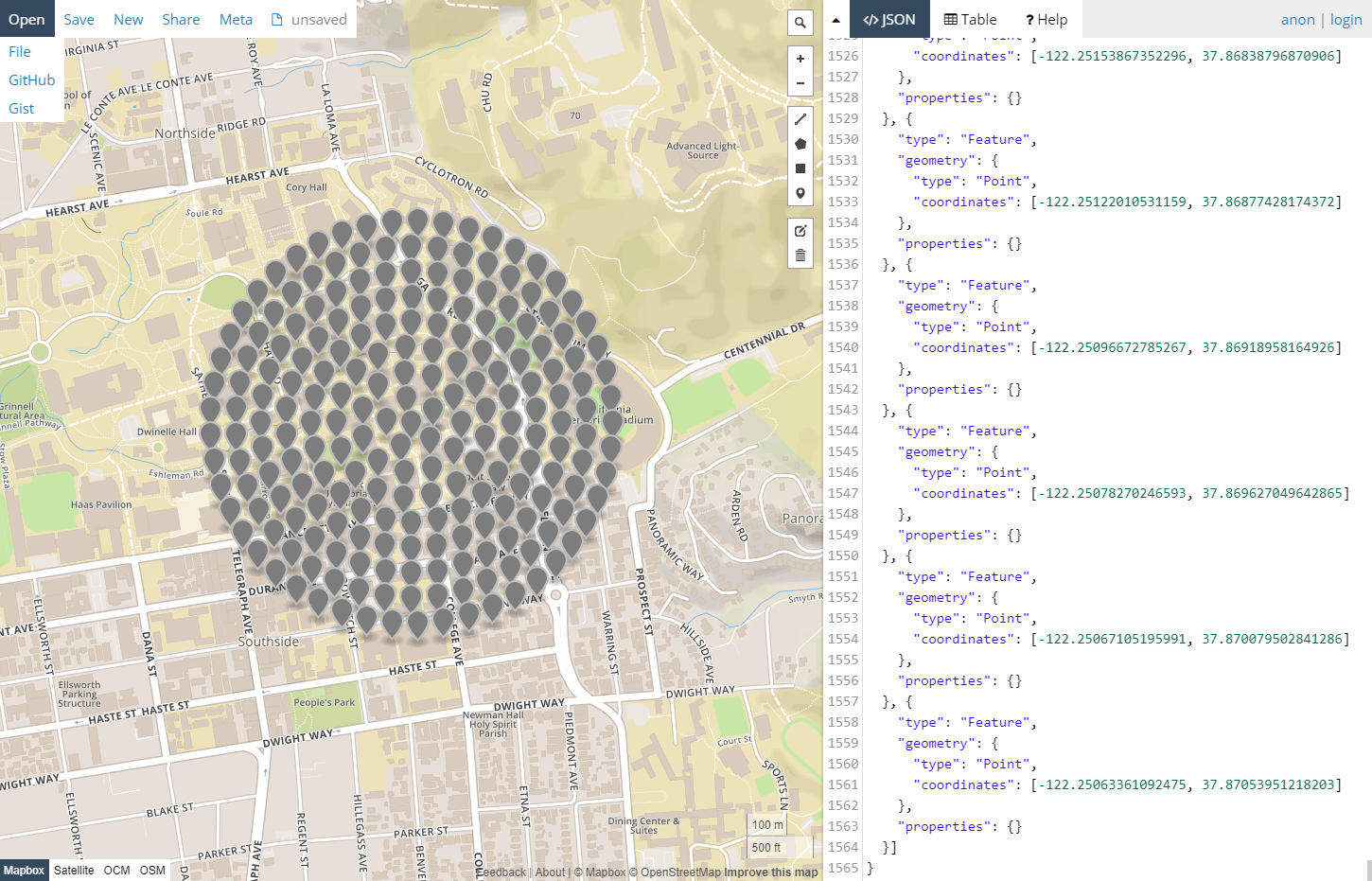
The collection of data begins with the identification of a geographic location of interest. Since the Google StreetView API operates on one geo-location at a time, and offers no mechanism for identifying multiple panoramic images near to given coordinate, the library offers a utility for plotting grids of coordinates centered on a given latitude and longitude in a number of basic configurations. These locations are returned as a single point collection in a .geojson file, as visualized below.
200 coordinate locations arranged in a circular grid pattern centered on Wurster Hall in Berkeley, California.
For this, methods were developed
for querying Google's StreetView API for
panoramic images that may be found
near to a location of interest.
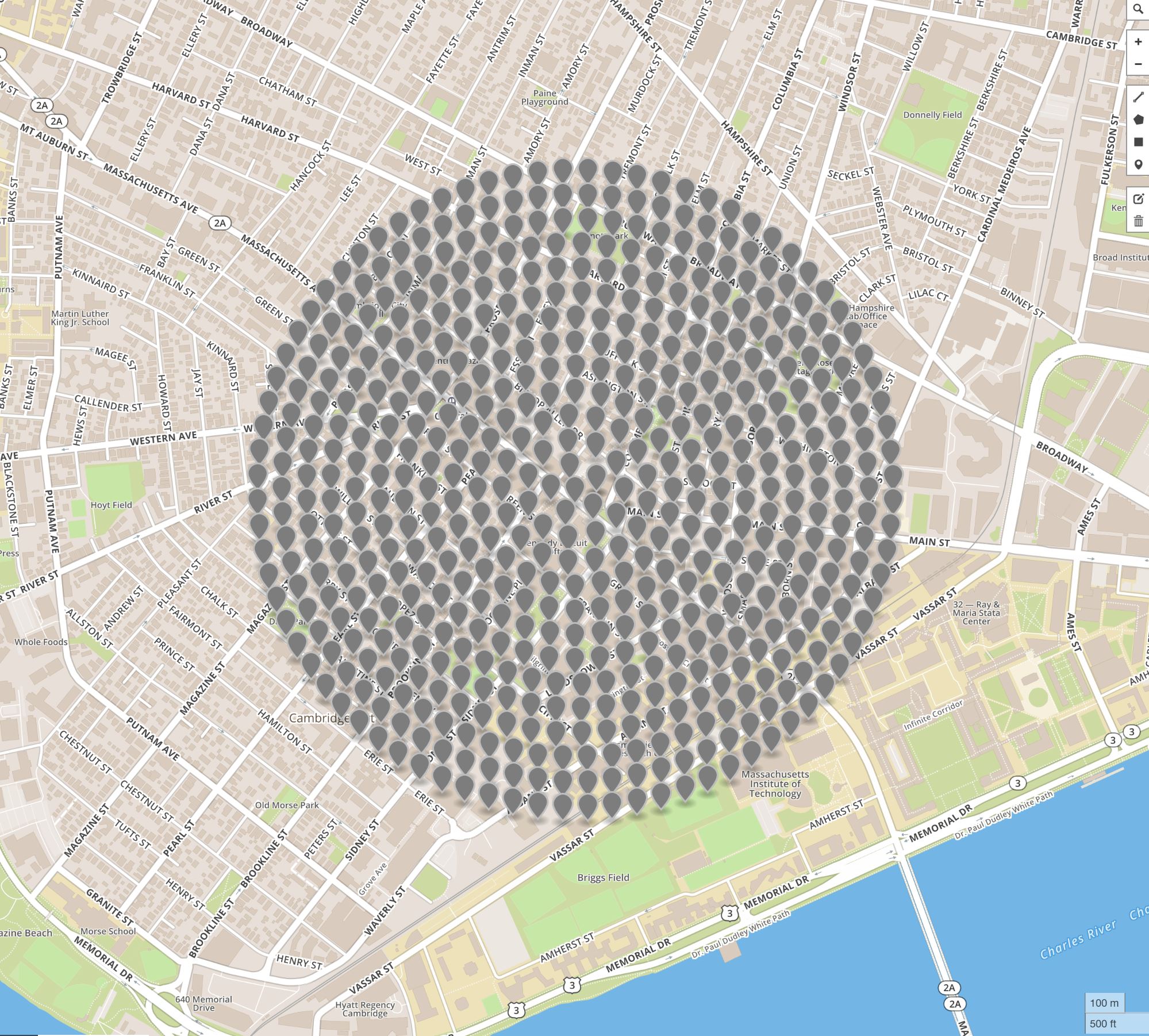
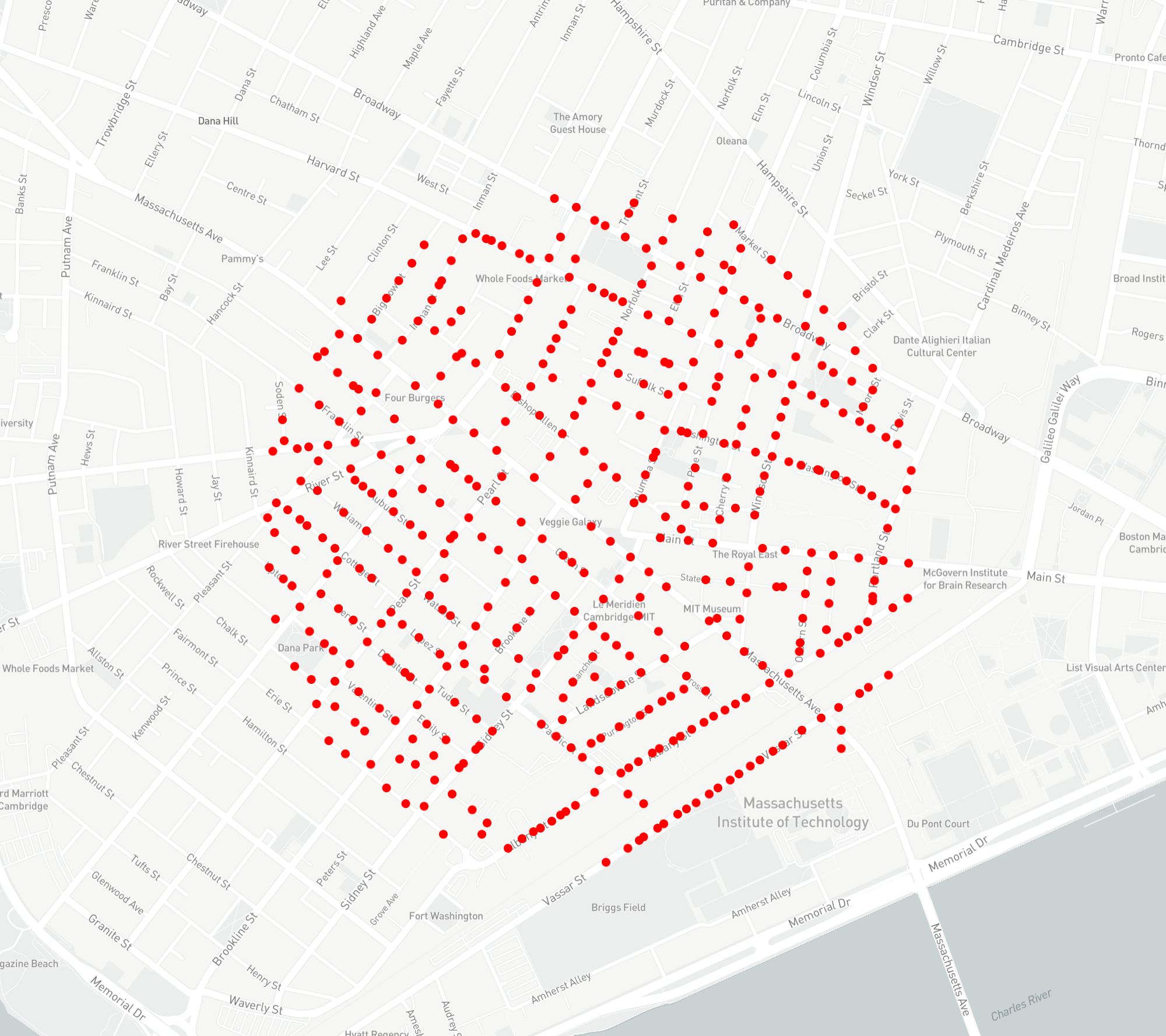
Coordinate locations of 560 requests for panoramic images in Cambridge, MA (left) and the actual geo-locations from which 470 panoramic images were taken (right).
These panoramas don't always exist where we want them to be.
on the left...
on the right...
With a collection of geo-locations of interest defined in .geojson format, we may proceed to query the Google StreetView API for panoramic images near these locations. Since the images at which panoramas are taken are likely not coincident with the given geo-locations of interest, a number of failure scenarios must be accommodated (such as two geo-locations of interest being near to the same panorama, or a geo-location returning no valid panorama). To this end, the given coordinates are first processed to identify a smaller list of locations from which panoramic images have been taken, each of which is identified by the API using a unique "panoid". For each of the urban contexts sampled in this scope of work, approximately 500 panoramas are sampled. As discussed in the sections below, information collected from this relatively limited set of panoramic images may be leveraged to produce a far larger set of training images.
Beyond the basic validation listed above, due to the structure of the data returned, even given a successful call to the API, a number of auxiliary processing steps are required. For example, because the API returns only a portion of a larger panorama as a tile of a set dimension (512 pixels square at the time of writing), these must be aggregated to arrive at a full 1:2 proportioned equirectangular image.
Next,
once we had acquired these panoramic images,
each must be processed
to serve as training data
for one of two ML models that were employed.
This first involved a bit of transformation.
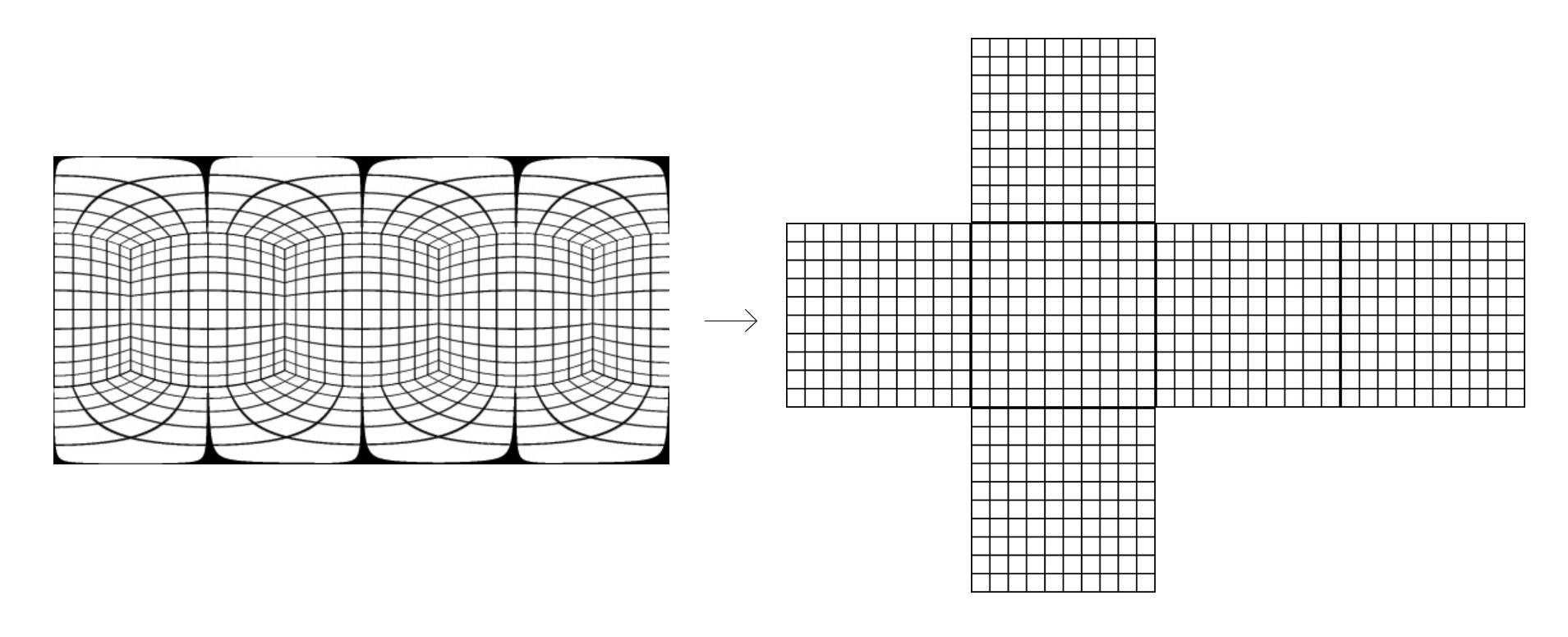
Here we the see the mapping
from the equirectangular image of the panorama
to a "cubemap" projection of six images,
two of which (sky and ground) were discarded
Once in this format,
the images collected were lightly curated,
Most notable among these auxiliary processing steps is the collection of depth information related to each StreetView panorama. Although it is not made clear from the StreetView interface, many two-dimensional panoramas provided by this service also hold some rudimentary three-dimensional data that describes objects in the urban scene (typically building forms). At the time of writing, given the unique "panoid" of a panorama, this three-dimensional information may be obtained via an unlisted API separate from the official StreetView API. This three-dimensional information is not described as a depthmap (in which the value of each pixel of an image is related to the distance of an object from the camera), as this project requires, but rather as a base-64 encoded collection of some number of oriented three-dimensional planes, presumably with the StreetView camera as the world origin. At this stage, this information is simply recorded as the base-64 string that is returned by the API, with any conversion of this vector geometry into raster information is left for a later step.
In summary, the collection of data begins with the defining of a single geographic point of interest, and results in the compilation of several hundred samples that may be further processed for training, each of which includes: an equalrectangular panoramic image, a set of three-dimensional planes that describe occluding objects in the described scene encoded as a base-64 string, and a set of related metadata (such as geo-location, date that the photo was taken, etc). In anticipation of the data curation step, this information is simply stored in a directory structure as collections of JPG and JSON files.
Data Curation
With the initial data collection complete, the data curation step is simple. Here, any unwanted or inappropriately formatted panoramic images are hand-culled from those downloaded in the initial collection. These may include: panoramas for which depth information is not available, panoramas that do not depict urban places (such as interior scenes), and, more subjectively, any panoramas that do not exhibit the desired qualities of place. While this last category of images might arguably be included in the training set in order to arrive at a more objective representation of a site, in this project, we opted to curate training sets with more intention in order to assess the degree to which the representation of a desired spatial atmosphere is achievable. The method of curation is exceedingly simple: the JPG files associated with any unwanted panoramas may simply be deleted from the file structure, an action which is anticipated by the subsequent processing scripts.
With a set of images
related to a given urban place
collected and curated,
the task of the data processing step
is to prepare this set of images
for their role in training a GAN model.
It turns out that
there's more data hiding underneath
each Google Street Map panorama
that is helpful in this endeavor.
Although it is not made clear
from the StreetView interface,
many two-dimensional panoramas
provided by this service
also hold some
rudimentary three-dimensional data
that describes objects in the urban scene
(typically building forms).
Data Processing
With a set of images related to a given urban place collected and curated, the task of the data processing step is to prepare this set of images for their role in training a GAN model. Although we target two different GAN architectures in this project, each of which exhibits different requirements for training, these are similar enough as to be well supported by the same data processing procedures. In this section, we outline the steps required for the transformation of the data described above (equalrectangular panoramic images, three-dimensional occluding planes, and assorted metadata) into appropriate training data. In summary, this training data is best described as pairs of related square-cropped raster images: one RGB image that represents a crop of a larger panorama image scene, and another greyscale image that represents the "depthmap" of this scene, with the value of each pixel representing the minimum distance from the camera to any occluding objects.
(left) A greyscale depthmap image of a scene in downtown Berkeley, CA (right) An RGB sceneographic image of a scene in downtown Berkeley, CA.
This three-dimensional information
is not served up as an image,
as this project requires,
but rather as a base-64 encoded collection
of some number of oriented three-dimensional planes,
with the StreetView camera as the world origin.
With some cajoling, we can arrive at the paring we see here.
On the right, a sceneographic image,
and on the left, a depthmap
in which the value of each pixel of an image
is related to the distance of an object
from the camera
Depthmap and sceneographic image pairs.
With this pairing in hand,
we can sample
the depthmap-scenographic panoramic pair of images
into the cropped pairing we see here.
this cropping allows us to perform
a bit of what is known as "data augmentation"
The aim of data augmentation
is to get more data for training.
The production of the RGB cropped images is largely straightforward, with just one process worthy of mention here: The equalrectangular projection of the panoramic images must be transformed to arrive the cubic environment map that better approximates what we expect for the synthetic images we aim to produce. This is accomplished following previous work describing the relevant conversion ( Bourke, 2006 ). It is noteworthy that the same panoramic image may be arbitrarily rotated along the z-axis (a transformation equivalent to a horizontal rotation of the cube) to produce slight variations of the same scene that may still be seamlessly tiled together. Expanding the breadth of training sets through slight transformations in this manner, a practice known as "data augmentation", is a common practice in ML ( Wang and Perez, 2017 ). In the samples described below, urban scene data has been augmented by performing two such rotations: one at 30 degrees, and another at 60 degrees.
Data augmentation by rotation by 0 degrees (left) 30 degrees (middle) 60 degrees (right).
Since a panoramic image
may be arbitrarily rotated along the z-axis
(a transformation equivalent
to a horizontal rotation of the cube)
to produce slight variations
of the same scene
that may still be
seamlessly tiled together.
Basically, we're simply expanding
the breadth of our training set
through slight image transformations
such as the ones we see here.
So, why does it matter
that we can collect pairs of images
that demonstrate a connection between
a scenographic image of a place
and a depthmap of a place?
To understand that,
we'll need to know a bit more
about the specfic ML models
that are employed on the project.
In that the relevant source data arrives as a base-64 encoded string describing sets of three-dimensional planes, the production of depthmap raster images is considerably more involved. Following on precedent work ( Wagener 2013 ), functions are here developed for the decoding this information, the conversion of the decoded data into a geometric description of a collection of planes, and for the performing the necessary ray-plane intersection operations to produce a raster depthmap.
In summary, the data preparation step for any given urban place begins with a curated collection of panoramic equalrectangular images and related information (including a description of occluding planes), and results in two sets of cubemap projection images: one set of RGB images that describe an urban scene, and one set of greyscale images that describe the effective depth of objects in that scene. Depending upon the data augmentation at play, certain features of the depicted place may appear multiple times in the resulting data, although from slightly different points of view. Image collections structured in this way are precisely what is necessary for the next stage of this process, the training of GAN models.
Model Training
Here we present the processes by the training data prepared above is used to train GAN models to produce synthetic images of urban places. Two distinct architectures are employed, Pix2Pix ( Isola et al., 2016 ) and StyleGAN ( Karras et al., 2018 ), each of which is detailed in the sections below.
Recent scholarly work ( Sculley et al., 2018 ), as well as a casual review of on-line training literature and discussion boards, reveals that the effective training of a GAN model is not an exact science. Although the pace of developments in ML more broadly has been striking, as Sculley et al. notes, "the rate of empirical advancement may not have been matched by consistent increase in the level of empirical rigor" (1). This is to say that empirical standards to guide the successful training of ML models have not yet been established. As such, given the relatively nascent state of the art in GAN training, what is offered below is presented as an account of the processes by which models specific to this scope of work were trained. These are intended to be taken as a valid starting point for future work, but not as an articulation of best practices.
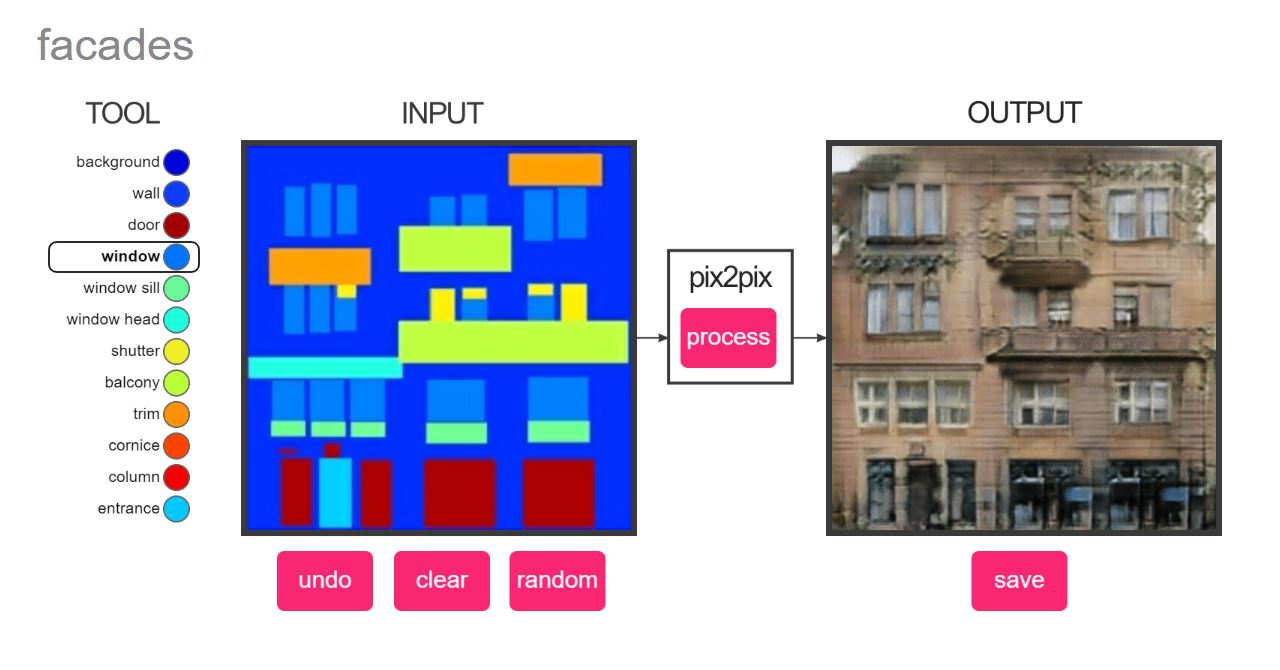
Pix2Pix
Pix2Pix ( Isola et al., 2016 ) is an architecture for a particular kind of GAN: a conditional adversarial network that learns a mapping from a given input image to a desired output image. From the perspective of a user of a trained Pix2Pix model, we offer an input image that conforms to some mapping convention (such as a color-coded diagram of a facade, or an edge drawing of a cat) and receive in return an image that results from the transformation of this input into some desired output (such as a photographic representation of a facade, or of a cat).
Synthetic image artifacts encountered while training.
The particulars that guide the training of a Pix2Pix model strongly depend upon the specifics of the implementation employed. This project relies upon a "high-definition" (up to 2048px x 1024px) version of this architecture implemented in Pytorch ( Wang, 2019 ). To adapt to the task at hand, some modifications of this implementation are required: to account for the computing resources at hand, models are trained to produce images at 512px square; to accommodate the limited computational resources at hand, training for each site is only conducted to 200 epochs; to correct problems with unwanted artifacts forming in cases of low-contrast source images, as seen in the figure below, the padding was adjusted to 0 and the learning rate set to 0.0008.
Employing the configuration described above, both RGB scene data and greyscale depthmap data collected from the nine urban places was used to train nine separate Pix2Pix models. The processing of all nine models on a dedicated local computer (GeForce GTX 1080 Ti 11GB graphics card, 2.8 GHz 6-core processor) required several months of active training time to complete. Once trained, each model operates as implied by the nature of a conditional GAN and by the structure of the training data: given a greyscale depthmap image that describes a desired three-dimensional urban scene, a synthetic RGB sceneographic image is returned.
Since these models are trained on subsets of data segregated by site, each model produces synthetic images specific to just one urban place: the Rotterdam model produces images that "feel" like Rotterdam, while the San Francisco model generates ones that appear more like San Francisco. This feature allows for direct comparisons to be drawn, as illustrated by the nearby figure and discussed more fully in a section below.
Results derived from Pix2Pix model: synthetic images of Rotterdam, NL (right) and San Francisco, CA (left).
StyleGAN
In contrast with a traditional GAN architecture, StyleGAN ( Karras et al., 2018] ) draws from "style transfer" techniques to offer an alternative design for the generator portion of the GAN that separates coarse image features (such as head pose when trained on human faces) from fine or textural features (such as hair and freckles).
Here, in comparison to the Pix2Pix model, the user experience is quite different: rather than operating by mapping an input image to a desired output, users select a pair of images from within the latent space of a trained model, and hybridize them. Rather than a simple interpolation between points in latent space, however, these hybrids correspond to the coarse and fine features of the given pair.
As above, the particulars that guide the training of a StyleGAN model strongly depend upon the specifics of the implementation. This project relies on the official TensorFlow implementation of StyleGAN ( Karras, 2019 ), which was employed without modification to train a single model on a combination of RGB sceneographic data drawn from all nine urban places. The processing of the combined dataset on a dedicated local computer (see specifications above) required approximately ten days of training time to produce a model capable of the results shown below.
Fake images drawn from all nine sites studied.
Once trained, the model may be queried either by sampling locations in latent space, or by providing coarse-fine pairs of locations in latent space to more precisely control different aspects of the synthetic image. Building upon the former technique of taking samples in latent space, linear sequences of samples may be combined to produce animations such as the ones displayed below.
Image Generation
Three methods for the structured exploration of these trained GAN models are presented here.
A depthmap (left) and cooresponding images for Jacksonville, FL (middle) and Rotterdam, NL (right).
The first image generation method relies on the Pix2Pix models, and offers the most controlled comparison of the three studies. Here, greyscale depthmap images are produced by sampling a scene described in a 3d CAD model. These depthmaps of constructed scenes are then used as the source image by which the Pix2Pix models for each urban place produces a synthetic photographic scene. By providing precisely the same input to models trained on different urban places, direct comparisons between the salient features picked up by the transformation models may be made.
For example, while each of the synthetic images below were produced by sampling the same depthmap, we can clearly see those imagistic properties that characterize each of the urban places sampled. A large massing that appears in the depthmap is interpreted by the Rotterdam model as a large brick housing block, as is typical in the Dutch city, while the Pickwick Park model renders this massing in a manner typical of the Northern Florida flora, suggesting the mass of a mossy Live Oak. A long and receding urban wall is broken up by the Alamo Square model into a series of small scale forms, an interpretation that expresses the massing of a line of Edwardian townhouses that dominate this San Francisco neighborhood; this same urban form is understood as something resembling a red-brick industrial warehouse building by the model trained on images from the Bushwick area of Brooklyn.
The other two image generation methods developed here rely on the StyleGAN models.
Like the method discussed above, the first of these two offers opportunities for comparisons to be drawn between the urban places sampled. Using the StyleGAN interface as it was intended by its authors, it is possible to separately assert control over the fine and coarse aspects of generated images. The interface that results may be seen as the design of urban scenes "by example": the user need only offer examples of images that contain desired features of a place, without explicitly stating what these are, where they came from, or how to construct them. In the context of this study, as above, this allows for comparisons between urban places to be conducted. For example, the nearby figure demonstrates how coarse features and fine features may be combined to form new scenes that hybridize aspects of existing scenes.
Synthetic urban places generated by StyleGAN. Vertical columns define course features, such as camera direction and orientation, while horizontal rows define fine features, such as textures, colors, and lighting effects of each urban place.
Finally, a method for generating animations by sampling linear sequences of the latent space of images implied by the StyleGAN model is developed. While not directly supportive of a controlled comparative study of urban places, these animations do offer insight into the structure of the latent space of the StyleGAN model, including which features and scenes are similarly parameterized, and which are far from one another.
SRGAN
Due to limitations of computing power available at this time, the models described above are limited to producing images of only 512px square. While this resolution is sufficient for the purposes of this study, it is less than desirable for the production of images suitable for printing at sizes appropriate for display. As such, auxiliary techniques are here developed for up-sampling these synthetic images while maintaining the fidelity at which they speak to their related contexts.
The process of estimating a high-resolution image given its low-resolution counterpart is termed "super-resolution". While a wide variety of approaches to super-resolution have been developed for some time ( Yang et al., 2007 ), this project employs an implementation of one approach that uses a GAN to up-sample a given image based upon the fine-image features learned from a given dataset ( Ledig et al., 2017 ). This approach allows us to add information to low-resolutions images that is specific to their origin; that is, specific to the urban places from which they are derived. The result is the addition of details, textures, and edges that are not generic, but rather speak to the nature of the sites in question.
Results and Reflection
As described above, a GAN instrumentalizes the competition between two related neural networks.
A circular walk through the latent space of the StyleGAN model trained on all nine sites. Elements of San Francisco appear to blend with Oakland and Gainesville.
Since the effective result of this competition is the encoding of the tacit properties held in common by the given set of images, this project proposes that an interrogation of the synthetic images generated by the GAN will reveal certain properties useful in uncovering the nature of urban places.
A second circular walk through latent space. Here, the plotted circle is half the size, so changes are not as drastic. Gainesville and Bushwick each seem to be strongly present.
Relying on Norberg-Schulz's characterization of a "place", which is understood to mean a "space with a unique character", and to include those forms, textures, colors, and qualities of light that exemplify a particular urban location, we can see that the immediate aim has been met, as the initial results documented above exhibit imagistic features unique to each of the sites studied.
The latent dimensions plotted by this circle appear to correspond strongly with the camera direction.
Much work remains, however, to realize the larger aim of this project to develop tools that support tacit intent in architectural design.
Seamless transitions between Oakland, Jacksonville, and Gainesville.
Future work in this area includes the extension of the "design by example" paradigm from images of urban places, as demonstrated here, to more directly architectural representations, such as three-dimensional forms and spaces.