How do AI tools become instruments in creative design practice?
Kyle Steinfeld for the Bartlett B-Pro Prospectives History and Theory Lecture Series, 2021
I'm Kyle.
As you probably have deduced, I'm one of these "computation" people.
Like many others working in this area, I think quite a bit about the dynamic relationship between the creative practice of design and computational design methods.
I'd like to begin by contextualizing this talk within a larger question that resonates strongly in this corner of the world, which is:
"will AI provoke a new aesthetics in architecture?"
Can AI provoke a new aesthetics in architecture?
Others have speculated on the possible emergence of an architectural aesthetics catalyzed by certain technologies related to AI.
Implicit in this project is that we can observe a relationship between certain actions in culture and certain responses in visual / spatial style in architecture.
I think it is fair to draw a comparison here: just as the "Machine Aesthetic" arose in response to industrialization, those of us interested in design and computation might speculate upon which aesthetic mechanisms are appropriate in this age of automation.
For example, we have recently heard convincing arguments for concepts such as defamiliarization, and the uncanny.
I am also motivated by these ideas, and am supportive of the larger cultural project, but in this talk I'd like to raise a different issue.
The current moment - let's call it "the age of automation" for now - is not only a moment of transformation that holds impact on aesthetics, but also introduces changes to the way design proceeds as a social activity, and how the tools of design perform as creative instruments.
Because of this, my question today is not about the emergence of a new aesthetic, but rather is an attempt to grapple with something that proceeds aesthetics.
My question today concerns the affordances of neural networks in creative practice.
To put it plainly:
What happens when AI tools become instruments in the hands of creative practitioners?
What happens when AI tools become instruments in the hands of creative practitioners?
What novel subjectivities might we embrace, and what fresh liberties does it engender?
Which of these new capacities should we avoid, and what are the important domains of action that are denied?
These questions revolve around the idea of "affordance".
Affordance refers to "the relationship between the properties of an object and the capabilities of an agent that determine just how the object could possibly be used"
(Norman, 1990, p11)
Affordance is a commonplace concept in certain design traditions. It is a widespread idea in UX design and industrial design, for example - but is something we hear less about in architectural circles (at least in my corner of the world).
"Affordance" used as a noun was first proposed by psychologist James Gibson in 1977, as a way of getting at the "complementarity" of an artifact and an agent (Gibson, 1986, p127).
This concept was later refined and adapted specifically for design by Don Norman in 1990 to describe "the relationship between the properties of an object and the capabilities of an agent that determine just how the object could possibly be used" (Norman, 1990, p11).
It is not without precedent to consider the concept of affordance in architecture, but typically in a different way than I'm thinking about it. In the past, architects have considered how environments might be reconsidered in terms of the affordances they offer their inhabitants.
There, the object is something like a building, and the agent is the occupant.
[ this page intentionally left blank ]
Here, I'd like us to consider the affordances that technologies like machine learning offer creative practitioners: the object is something like a neural net, and the agent is the designer.
This framing is an appealing compliment to questions of style and aesthetics, but is slightly adjacent.
In other words.
As things stand, designers have seen and have begun to grasp a set of potentially-transformative tools and techniques. To enable the development of a novel aesthetics appropriate to the times, these tools must become instruments in the hands of creative practitioners.
To understand how this happens, we must come to grips with the nature of this technology - we must understand things like neural networks as media.
I take this position because I can't help but understand new technologies of design through the lens of every other technology of design - as cognitive instruments, as means through which to think. As media.
The way I see it, we should understand neural networks the way we understand mylar, basswood, graphite, pixels, vectors, splines, control points, components.
These are all the same in that they can be understood as media and as supportive of certain forms of craft; they each support highly individualized practices, they each can be integrated into an iterative process with each step informing the next, we can find in each qualities of expression - of an author's "voice".
Its fine to think about the similarity of these media, and of neural networks taking its place among them, but designers select a particular media for how it positions them differently: how it uniquely links hand, mind, and imagination - how it might enable a different form of thought and a different sort of work.
This is why we choose one media over another.
So my question is this: how will the neural net figure in the history of architectural media? Looking back, how will we understand the impact of this technology, and in what situations we will find advantage in selecting it over other media?
What will the neural network do to the architectural imagination?
What is a neural net for?
In other words, what is a neural net for?
This is a question of affordances, and to begin to answer it requires coming at the question from at least two angles. Why two angles?
Think of a thing [for example, a trumpet]. We can understand the affordances of the thing via an examination of the morphology - its a curled up metal tube with a place that seems to fit my hand, it has one small end and one large end, there are some funny keys and it makes sounds when air passes through it. This morphological would get us somewhere, but we would learn entirely different lessons by examining a trumpet as an instrument of practice. There, we would find an expectedly wide range of related cultures of use from marching bands, to jazz ensembles, to ceremonies honoring fallen soldiers.
To understand how aesthetics can emerge in relationship to tools, we have to understand the contexts in which these tools become instruments.
To understand what a thing is "for", we have to understand the *both* the inherent properties of the thing, *and* the way it is understood by different cultures of practice.
With this in mind, I'd like to offer today the briefest of reflections on this first thing - about the inherent affordances of neural networks - and devote most of my time to views from practice... to things I've learned by engaging in creative machine learning design projects for a number of years.
Neural nets are patterns mapped on to other patterns with no structured internal representation.
So, A brief reflection here on the internal nature of neural nets.
It seems to me that because ML models are based on data, this technology is inherently (unavoidably) a reflective one - it is a medium that looks back. This tendency stands in sharp contrast to the tone of some of the dominant voices in design computation today, which have been rightly criticized as being largely ignorant of the past. It also stands in contrast with the dominant aesthetics of what we might think of as digital architecture.
In contrast with methods that seek to "capture the intent" of a designer, the affordances of ML concern the tacit, unspoken, and unintentional bits of the world as we find it.
It is a world described by the dataset.
This stands in opposition to practices such as parametric design, rule-based design, and emergent design, each of which provide tools that encourage us to decompose design problems into ever-smaller bits. We could observe that where instruments such as parametric design are about first principles, the internal affordances of machine-augmented design are quite different.
The currency of neural networks are "patterns". Their very nature is the mapping of input patterns to output patterns, with no structured intervening representation.
This leads me to a number of observations about the morphology of neural networks as creative instruments. Three "axioms" for how neural networks influence creative practice.
Neural nets are inherently historical instruments.
Insofar as they are trained on data derived from the world, they generate patterns drawn from the world.
Historical - insofar as they match patterns to patterns, their fundamental operation is recognition.
Neural nets are inherently imagistic instruments.
Insofar as they match patterns to patterns, their fundamental operation is recognition.
Imagistic - insofar as they match patterns to patterns, the currency of generative neural nets is recognition.
Neural nets are inherently curatorial instruments.
Whereas CAD positions us as composers, and parametric design positions us as logicstitians, NN position us as curators.
Curatorial - whereas CAD positions us as composers, and parametric design positions us as logicstitians, generative neural nets position us as curators.
Fresh Eyes, 2017
Fresh Eyes
A framework for the application of machine learning to generative architectural design
Adam Menges, Kat Park, Kyle Steinfeld, Samantha Walker, SOM
2017
Almost Home Kyle Steinfeld, 2019
This project represents an effort to apply Machine Learning techniques to Generative Architectural Design, and was motivated through a workshop offered at the Smart Geometry conference in 2018 in Toronto. Through the development of the framework described here, we seek to demonstrate that generative evaluation may be seen as a new locus of subjectivity in design.
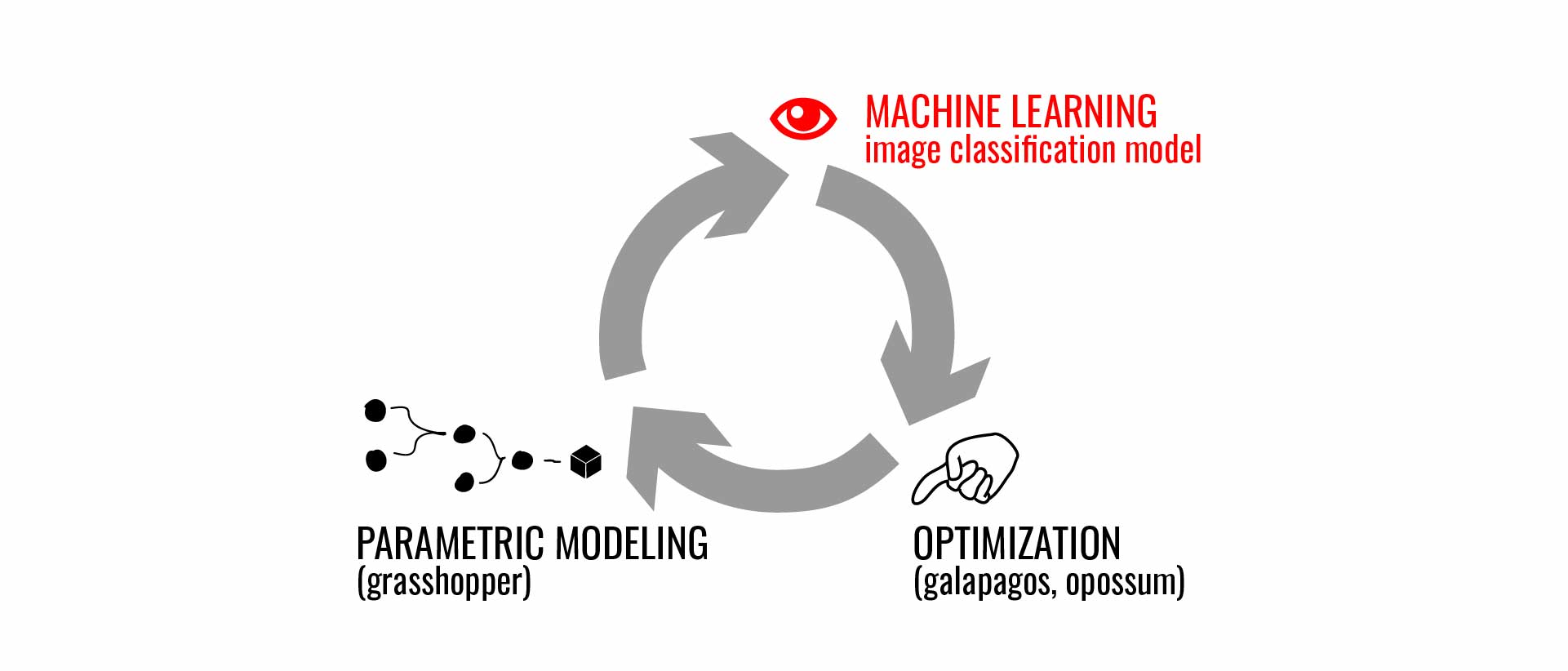
The standard generative design cycle, with an image classification model standing in for the evaluation step. Kyle Steinfeld, 2018
Proposed here is a modest modification of a 3-step process that is well-known in generative architectural design, and that proceeds as: generate, evaluate, iterate. In place of the typical approaches to the evaluation step, we propose to employ a machine learning process: a neural net trained to perform image classification.
For example, I'll show an example of a generative design cycle that seeks to maximally satisfy a neural net trained to recognize various forms of single-family homes.
New terms for the generative design cycle. Kyle Steinfeld, 2018
This modified process is different enough from traditional methods as to warrant an adjustment of our terms,
such that "Generate, Evaluate, Iterate" becomes "Actor, Critic, Stage"
I'll use these modified terms through the remainder of this presentation.
One important contribution of the cluster involved the developing of methods for **describing architectural forms and spaces as images**, and in ways that allow the salient qualities of form and space to be captured by our critic.
To make this work, an important contribution of this work involves the developing of methods for describing architectural forms and spaces as images and in ways that allow the salient qualities of form and space to be captured by our critic.
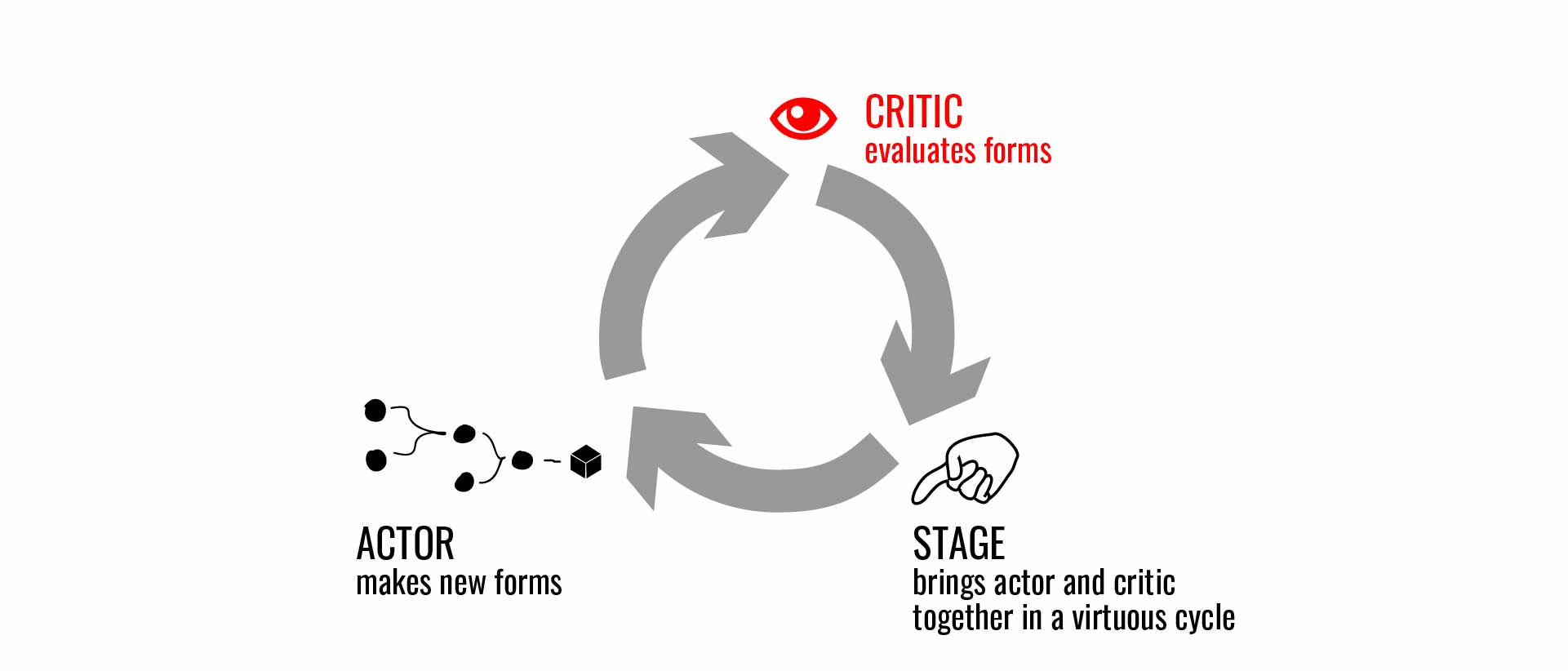
An actor and critic coming together on a stage. A critic is trained on 3d models that describe typologies of detached single-family homes, such as "cape cod house", "shotgun", "dogtrot", etc..
To illustrate how these pieces go together, we see in this animation an actor and critic coming together on a stage.
Here, a critic is trained on 3d models that describe typologies of detached single-family homes: cape cod house, shotgun, dogtrot, etc..
The job of the critic is to evaluate the performance of an actor. In this case, our actor generates house-like forms, such as the ones we see flashing by in this animation.
The job of the critic is to evaluate the performance of an actor, and in this case, our actor generates house-like forms, such as the ones we see flashing by in this animation.
These two are brought together in an optimization, wherein the actor generates new potential house forms, these forms are scored by the critic in terms of how much they resemble a known type of house, such as the California Eichler style shown here, and then the process iterates in a classic optimization.
These two are brought together in an optimization, wherein the actor generates new potential house forms, these forms are scored by the critic in terms of how much they resemble a known type of house, and then the process iterates in a classic optimization.
By modestly adjusting the nature of the evaluation step of the generative design process, we find a way forward from optimizing for **quantifiable objectives**, as is typical in generative design to optimizing for more **qualitative objectives**, such as architectural typology or spatial experience
and so, by modestly adjusting the nature of the evaluation step of the generative design process, we find a way forward from optimizing for quantifiable objectives, as is typical in generative design to optimizing for more qualitative objectives, such as architectural typology or spatial experience
Not Far From Home Kyle Steinfeld, 2018 Shown at the NeurIPS 2018 Machine Learning for Creativity and Design www.aiartonline.com/design/kyle-steinfeld/
Just a closing note to say that an unintended by-product of this work back in 2017 was, as far as I know, the first GAN (generative adversarial network) trained to produce three-dimensional architectural forms.
We'll come back to this.
GAN Loci, 2018
GAN Loci
Imaging Place using Generative Adversarial Networks
Kyle Steinfeld
2018
Results derived from Pix2Pix model: synthetic images of Rotterdam, NL (right) and San Francisco, CA (left).
This second project applies the now-ubiquitous GAN, to produce synthetic images intended to capture the predominant visual properties of urban places.
Through this, the project clearly illustrates the affordances of neural networks in "capturing the tacit".
What do I mean by "capturing the tacit"?
Well, in this case, I'm referring to a computational approach to documenting what we might understand as the "Genius Loci" of a city, which includes those forms, textures, colors, and qualities of light that exemplify a particular urban location and that set it apart from similar places.
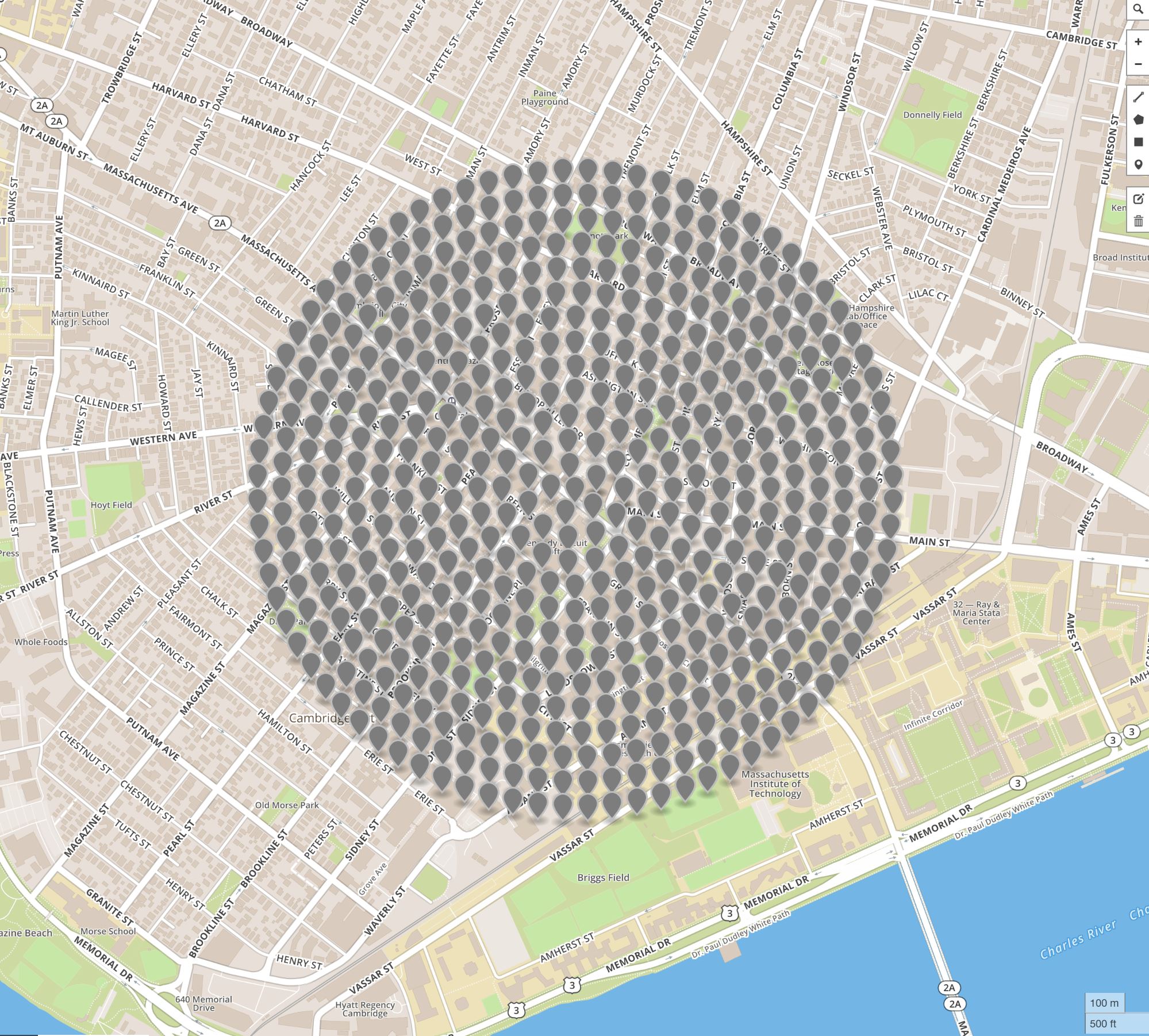
Panoramas don't always exist where we want them to be. Coordinate locations of 560 requests for panoramic images in Cambridge, MA (left) and the actual geo-locations from which 470 panoramic images were taken (right).
To this end, methods were developed for the collection of urban image data, for the necessary processing and formatting of this data, and for the training of two known computational statistical models that identify visual patterns distinct to a given site and that reproduce these patterns to generate new images.
Nine distinct urban contexts across six cities in the US and Europe were imaged in this way.
(left) A greyscale depthmap image of a scene in downtown Berkeley, CA (right) An RGB sceneographic image of a scene in downtown Berkeley, CA.
Here we see some of the mechanisms by which this was accomplished.
Depthmap and sceneographic image pairs.
In summary, by illicitly scraping Google Street View, we can extract depthmap-scenographic pairs of panoramic images. This allows a neural net to be trained on the relationship between spatial information (bottom) and photographic information (top).
Greyscale depthmap images are produced by sampling a scene described in a 3d CAD model. These depthmaps of constructed scenes are then used as the source image by which the Pix2Pix models for each urban place produces a synthetic photographic scene. By providing precisely the same input to models trained on different urban places, direct comparisons between the salient features picked up by the transformation models may be made. A depthmap (left) and cooresponding images for Jacksonville, FL (middle) and Rotterdam, NL (right).
With this relationship in hand, we can draw comparisons, and "dress up" the exact same spatial information (left) which may or may not have come from a real place, with imagistic information related to different places.
Here we see two synthetic scenes - one "dressed up" like Jacksonville, FL (where I was born) and a second "dressed" like Rotterdam, NL (which I briefly called home).
Another set of "dressings" of the same spatial scene.
So, the product of this work is not a tool for the design of cities or building forms, but rather a method for the synthetic imaging of existing places.
A circular walk through the latent space of the StyleGAN model trained on all nine sites. Elements of San Francisco appear to blend with Oakland and Gainesville.
Since the effective result of this competition is the encoding of the tacit properties held in common by the given set of images, this project proposes that an interrogation of the synthetic images generated by the GAN will reveal certain properties useful in uncovering the nature of urban places.
Still, the work may be situated in the context of CAD, as it is suggestive of a new approach to computer-assistance.
In contrast with, for example, parametric tools that seek to capture the explicit intention of their user...
A circular walk through latent space. Here, the plotted circle is half the size, so changes are not as drastic. Gainesville and Bushwick each seem to be strongly present.
Relying on Norberg-Schulz's characterization of a "place", understood to mean a "space with a unique character" and to include those forms, textures, colors, and qualities of light that exemplify a particular urban location, we can see that initial results exhibit imagistic features unique to each of the sites studied.
... in applying computational statistical methods to the production of images that speak to the implicit qualities that constitute a place, this project demonstrates the unique advantages offered by such methods in capturing and expressing the tacit.
Drawn Together, 2020
Sketch2Pix
An interactive application for architectural sketching
augmented by automated image-to-image translation
Kyle Steinfeld
2020
(left) AI Augmented Axonometric Sketch, Robert Carrasco, 2020 (right) AI Augmented Landscape Drawing, Sarah Dey, 2020
This last project centered on the development and testing of an augmented architectural drawing tool Sketch2Pix: an interactive application that supports architectural sketching augmented by automated image-to-image translation processes.
A Sketch2Pix "brush" trained on images of a strawberry, and the use of this brush. Nehal Jain, 2020
Students first utilized the Sketch2Pix tool to train an augmented drawing assistant - in the parlance of the studio, a "brush" - based on a selected piece of produce.
The work sought to expand the reach of what can be at times obscure and difficult-to-access technologies.
A Sketch2Pix "brush" trained on images of wooden dowel models, and the use of this brush. Robert Carrasco, Payam Golestani, Nehal Jain, and Tina Nguyen, 2020
Students next trained an augmented drawing assistant, or "brush", using more familiar subject matter: the architectural model. Here, students construct a series of non-scaled physical models that employ an intentional formal language common to academic design studios.
By removing certain technical barriers, and by facilitating access for creative design practitioners who may not be well-versed in the underlying technologies, we sought to understand what might happen when novice designers were enabled to craft and interact with their own augmented drawing assistant.
A Sketch2Pix "brush" trained on images of a plaster blob. Kyle Steinfeld, 2020
Selections of form included: a series of foam-core massing models; a collection of plaster "blob" models; and a third series of linear basswood matrix models. These models are then 3d scanned such that they may serve as the basis of a training set for a "brush".
The result is an augmented drawing assistant that transforms hand-drawn sketches into "deepfake" photographs of architectural models. These tools were then deployed in the service of the design of a dwelling for a specific site.
To this end, an undergraduate research studio was conducted at UC Berkeley in the Spring of 2020. Here, students trained their own neural networks to be their own bespoke augmented drawing assistants
The composition of a sketch using four distinct brushes, activating each multiple times. Kyle Steinfeld, 2020
We termed these our "brushes", each of which was trained on a designer's own data, and for a designer's own use in sketching architectural forms. You can see some of the processes of developing and employing them here.
This work included: the establishment of a training data set; the training and validation of a neural network model; the deploying of this model in a graphic sketching environment; and the configuration of the sketching environment to facilitate a "conversation" with an AI partner.
Given the novelty of the augmented sketching tools adopted by the studio, students are asked to engage in a practice of daily sketching, and to post these sketches for public display. This practice served to encourage increased competency with these tools. The primary conduit for the public display of this work is an Instagram hashtag related to the course: #ARCH100D. The graphic material found at this hashtag relates to each of the propositions listed here.
Sketching with these AI partners became a daily practice, and the studio was extraordinarily productive.
By introducing novice students to a set of experimental tools and processes based on ML techniques, the studio hoped to uncover those original practices or new subjectivities that might thereby arise.
Augmented drawings authored with the Sketch2Pix tool. From left to right: Daniel Barrio, Can Li, Nicholas Doeschlag, 2020.
Augmented drawings authored with the Sketch2Pix tool. From left to right: Tina Nguyen, Robert Carrasco, Leo Zhao, 2020.
More than unpacking of the details of this work, there are two reflections I would like to raise up as a way of framing what I'll talk about next.
First, we observe that the tools shown here function as a novel and effective form of early-design "provocateur".
ML generates forms and images
based on associations drawn
from a specific body of experience.
-
This suggests a new form of creative prompt:
"guided provocation".
We observe that an ML Generative model functions as a novel and effective form of early-design "provocateur", in the tradition of Eno, Schmidt, and Boulez. While similarly functioning to serve as a quasi-random "po" deliberately used to facilitate creative thinking, it is notable that the forms and images conjured by ML processes are not random, but rather are associations drawn from a specific body of experience (the training dataset) that may or may not be apparent to a user. This feature suggests a novel form of "guided" provocation, in which an author consciously selects the predilections of their drawing assistant to be provoked in an intentional way in relation to the particularities of a design problem.
It is notable that the forms and images conjured by ML processes are not random, but rather are associations drawn from a specific body of experience.
This feature suggests a novel form of "guided" provocation, in which an author consciously selects the predilections of their drawing assistant to be provoked in an intentional way in relation to the particularities of a design problem.
This is a non-obvious affordance of a neural net, and a form of subjectivity we might not have otherwise anticipated.
Finally, I would underscore what is perhaps a more obvious form of subjectivity offered by machine-augmented design.
Whereas
computer-aided design is compositional,
and parametric design is logistic,
computer-augmented design is curatorial.
We also highlight a new form of subjectivity offered by machine-augmented design. In the of training of Pix2Pix "brushes", including the critical step of crafting data sets for training, we find a new authorial position that should not be overlooked by designers engaging with this media. In stark contrast to other modes of computational authorship, such as parametric modeling, design action expressed through the defining of a training dataset is curatorial more than logistic or compositional. It is an action that may be regarded as uncomfortably indirect by designers new to the media: suggestive of imagistic traits more than deterministic of formal or geometric ones. This new locus of subjectivity holds broad ramifications for the future of computational design education, and suggests that connections must be strengthened with allied knowledge domains, such as data science and critical data studies.
In the of training of Pix2Pix "brushes", we find a new authorial position.
In stark contrast to other modes of computational authorship, design action expressed through the defining of a training dataset is **curatorial** more than logistic or compositional.
It is an action that may be regarded as uncomfortably indirect by designers new to the media: suggestive of imagistic traits more than deterministic of formal or geometric ones.
Artificialis Releivo, Ongoing
Ok. One last project.
So, it's one thing to talk about the possible futures of ML in design, and quite another to find applications in the present. To not only ask: "what is the neural net for?", but "what is the neural net for *right now*?"
This last project that I'll talk about today is ongoing, it's in active development, and I'd like to take a bit more time to unpack it because I think it speaks to the current state of things in the application on ML to design.
(left) Synthetic Oakland Kyle Steinfeld, 2018
(right, center) A single-family home in North Oakland Kyle Steinfeld, this morning.
The project began with the start of the pandemic.
The places you see here - this is where I live, this is my neighborhood in Oakland - and this is where I found myself confined in the lockdown of March of 2020. I spent quite a long time taking walks in this neighborhood with my kids, and as we walked - when I wasn't taking questions about The Legend of Zelda - I found myself thinking as I walked about the modest architecture of these buildings that are within walking distance of my home.
In particular, I started thinking about these ornamental elements such as you see here pictured on the right.
In the fever dream of the pandemic, I became obsessed with these little bits of architecture - how they're expressed as these little deformations of stucco that hold imagistic qualities. They can look like flowers or like soft-serve ice-cream. These kitch little pieces of - probably foam covered in plaster - are applied to recall some vague Western tradition - Greek, Roman, Italian, French... it's hard to tell, and it hardly matters.
(left) Entrance to the Carson Pirie Scott Building Louis Sullivan, 1903 Photograph by Hedrich-Blessing, 1960.
In their historicism, they play on our capacity for recognition and recall; In their constructed illusion of high relief, they play on our tendency to perceive three dimensional form. These little optical illusions sprinkled all over my neighborhood began to seem really important: they offer each dwelling something of an identity, and allow us to differentiate one otherwise unremarkable house from another.
Certainly, there's precedent for architects working in this way, as we see here.
It struck me that this modest and easily-overlooked medium of architectural expression is suggestive of a yet-to-be-explored domain of application for the technologies I've been experimenting with.
Certain strains of contemporary architectural form-making hold resonance with certain threads of imagistic pattern-making found in machine-augmented visual art.
One of these pieces operates on pixels, the other on polygons. Can we bring these two together?
Walking the streets of Oakland, it occured to me that certain strains of contemporary architectural form-making hold resonance with certain threads of imagistic pattern-making found in machine-augmented visual art.
It seemed plausible for there to be some resonance here - some way to make existing neural networks instrumental in this domain. To bring existing technologies, most of which are based on raster images such as you see on the right, to bring these to bear on a sort-of generative architectural sculptural ornament.
There is nothing inherent in the existing technology that leads us to raster images. Indeed, there are creative applications of machine learning that span different representations: from text-based models, to graph models, to even some models that operate on 3d boundary representations. However, some of the most well-developed technologies in this space grew out of problems in computer vision, and are built around raster images. And so, a major motivation of this project focuses on a question of representation.
After all the two images we see here appear to hold no important conceptual distinction, rather, the difference appears to me a matter of representation: one operates in pixels in 2d, the other in polygons in 3d. Can we bring these two together?
Can the raster representation that dominates much of the relevant technical foundational work in ML be adapted to describe architectural form in more robust ways?
A double-sided depthmap of a canonical CAD object. Here, the red channel represents a front-facing depthmap while the blue channel represents a back-facing depthmap.
So, with these thoughts in our heads, a team here at UC Berkeley and I got to work.
We sought to understand if the raster representation that dominates much of the relevant technical foundational work in ML could be adapted to describe architectural form in more robust ways.
Since our subject matter concerns architectural sculptural relief, initial experiments examined the illusion of depth in relief.
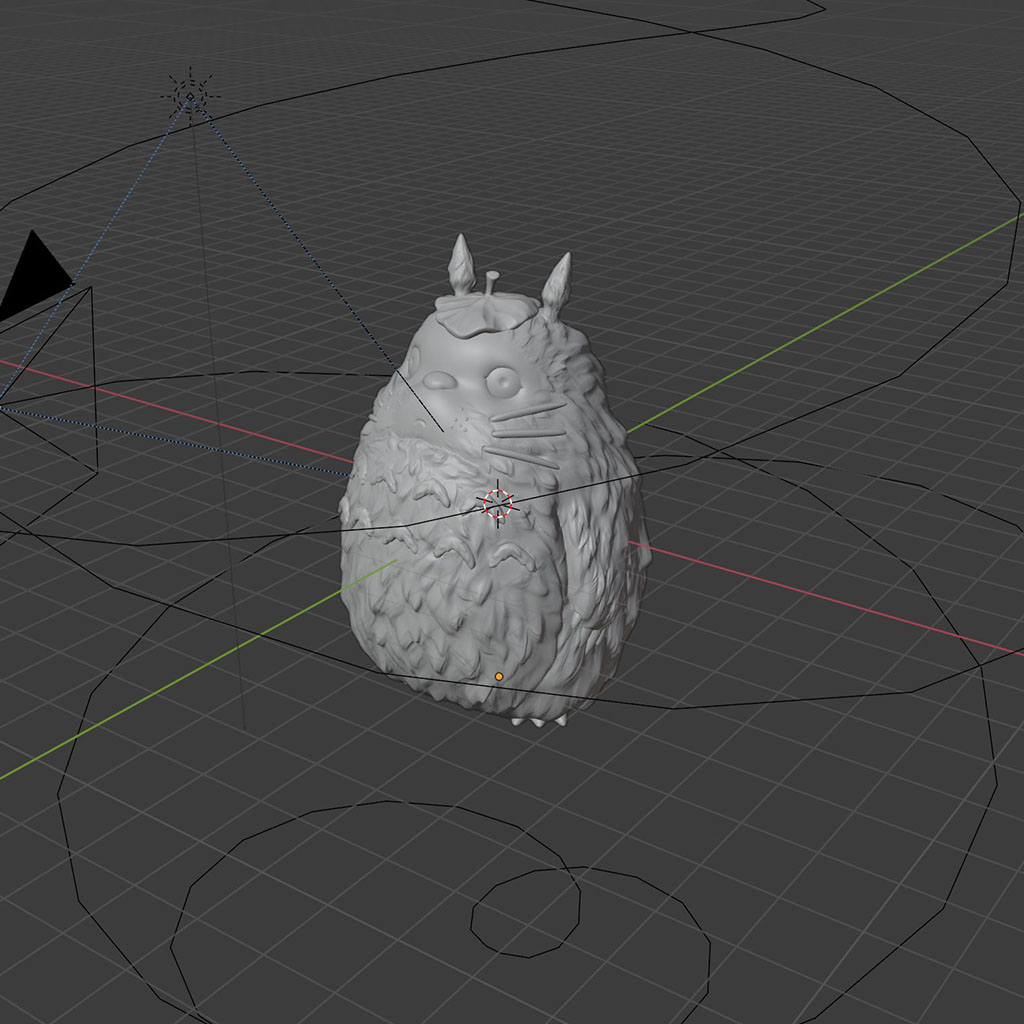
All hail the king of the forest!
Recalling the "Fresh Eyes" work from 2018, we began by experimenting with variations on a traditional depthmap.
In a "depthmap" (or heightfield) raster data is used to encode the displacement of a plane along a single axis - lighter pixels are displaced more, and darker pixels are displaced less. This format is well-known and is standard in a range of practices; from GIS representations of topography to "bump" mapped materials used in renderings.
As an initial experiment, we wanted to see if we could train a neural net to generate synthetic depthmaps that describe interesting forms.
A variation of a depthmap in which depth information from different directions is encoded into the separate channels of an RGB image.
To up the ante, we developed a "homebrew" variation of a depthmap that encodes depth information from different directions into the separate channels of an RGB image.
While it's a interesting technical question as to if a neural net can capture and reproduce patterns encoded in this way, we were also interested to know if our GAN was able to capture the "form language" of the test subjects shown here.
This, of course, is Squirtle... a Pokemon. On the previous slide was Totoro, king of the forest. I think you can see the form language we were hoping to reproduce.
Synthetic Pokemon figures described by a GAN-generated two-sided depthmap.
... and, as you can see here, we found some modest success!
Shown here is a collection of synthetic pokemon figures. These are not really fully 3d forms (maybe two-and-three-quarter dimensional?), but they are fully 3d printable (I can send you a file if you'd like) because they are produced by a GAN-generated two-sided depthmap.
We see the synthetic depthmap on the left, and a form derived from this map on the right.
Synthetic Pokemon figures described by a GAN-generated two-sided depthmap.
I would claim modest success with this early experiment for two reasons.
First, its clear that the architecture of this existing GAN (this is StyleGAN 2) successfully learned a distinct language of 3d(ish) forms described as raster data. The depthmap representation is somewhat abstracted away from the 3d geometry on which it was based, but the GAN learned it anyway. The results have a Pokemon "look" to them. That's a success.
Further, I find it compelling that a relationship is established here between a descriptive format (the depthmap) and a 3d form (the Pokemon shape) that not only is amenable to being learned by a neural net, but also is suggestive of a fabrication process.
What I mean is that the constraints of a two-sided depthmap map nicely onto certain fabrication constraints related to, say, CNC milling.
It's cool that we could mill one of these shapes quite easily.
Training animation for a 3-channel relief of human figures
With this early success under our belt, the project drifted a bit as we attempted to extend this technique into the more complex scenes and more detailed forms that we felt were necessary to match our ambitions for architectural application.
Synthetic 3-channel relief of human figures
We built a one-sided "layered" variation of a 3-channel depthmap intended to capture human forms and gestures.
meh.
The results were a little "meh".
There were several reasons for this probably... our datasets remained quite small, the artificiality of the subject matter was less than compelling, etc.
Ultimately, I feel we began to encounter the limits of a tradtional depthmap. No matter how many channels we introduced or directions we extruded from, the synthetic forms still felt quite "flat" and "directional" in comparison to those precedents that really inspired us.
If we were to see the project progress, we would need to shift our thinking somehow. We decided to look a little further afield to raster representations that could more robustly describe the forms we were after.
Which is precisely what we found in a bizarre raster representation drawn from an obscure corner of the world of 3d animation.
A vector displacement map applied in the Mudbox CAD software YouTube user mudoglu
What is this bizzare form of raster representation?
Well, it's called a "vector displacement map", and it turns out to be a pretty good way of representing sculptural form in a way that is understandable to a raster-based neural network.
Vector displacement is a relatively obscure approach to digital modeling developed for character design and animation applications.
This format addresses the problem of depicting geometrically detailed sculptural forms in a lightweight and portable way. Rather than relying on 3d geometry for certain details, a 2d raster image is employed. When this image is applied to a 3d surface as an image map, it can describe a "displaced" height and direction relative to this surface.
In a vector displacement map, displacements are stored as vectors of arbitrary length and direction. This vector information is separated into its X,Y, and Z components and is stored as the RGB channels of a full-color raster image.
A simple way of understanding this approach is to refer to its ancestor - the depth map that I discussed earlier. These are sometimes called "height-fields" or "bump maps", and if you've worked with rendering software, you're probably aware of these terms. In this "regular" displacement map, a greyscale image is mapped onto a 3d surface, which is then displaced during the rendering process.
A vector displacement map functions in a similar way, but extends the technique to capture a broader range of forms. Here, displacements are stored not as "pushes" or "pulls" along a single direction, but rather along a vector of arbitrary length and direction. This vector information is separated into its X,Y, and Z components and is stored as the RGB channels of a full-color raster image.
(left) Creature design by Nicolas Swijngedau www.facebook.com/NicolasDesign
Vector displacement maps have found relatively widespread application in the niche practice of 3d character animation, where this same technique has also been used to transfer details from one model to another, and is used as a "stencil" or "stamp" tool in 3d sculpting applications.
(right) A single-family home in North Oakland Kyle Steinfeld, this morning.
To my knowledge, vector displacement maps have not been used in architectural design... but they should!
There seems to be some real resonance between the sculpting interfaces offered by contemporary character modeling software, such as Z-brush shown on the left, and the kitchy stucco deformations that dominate North Oakland.
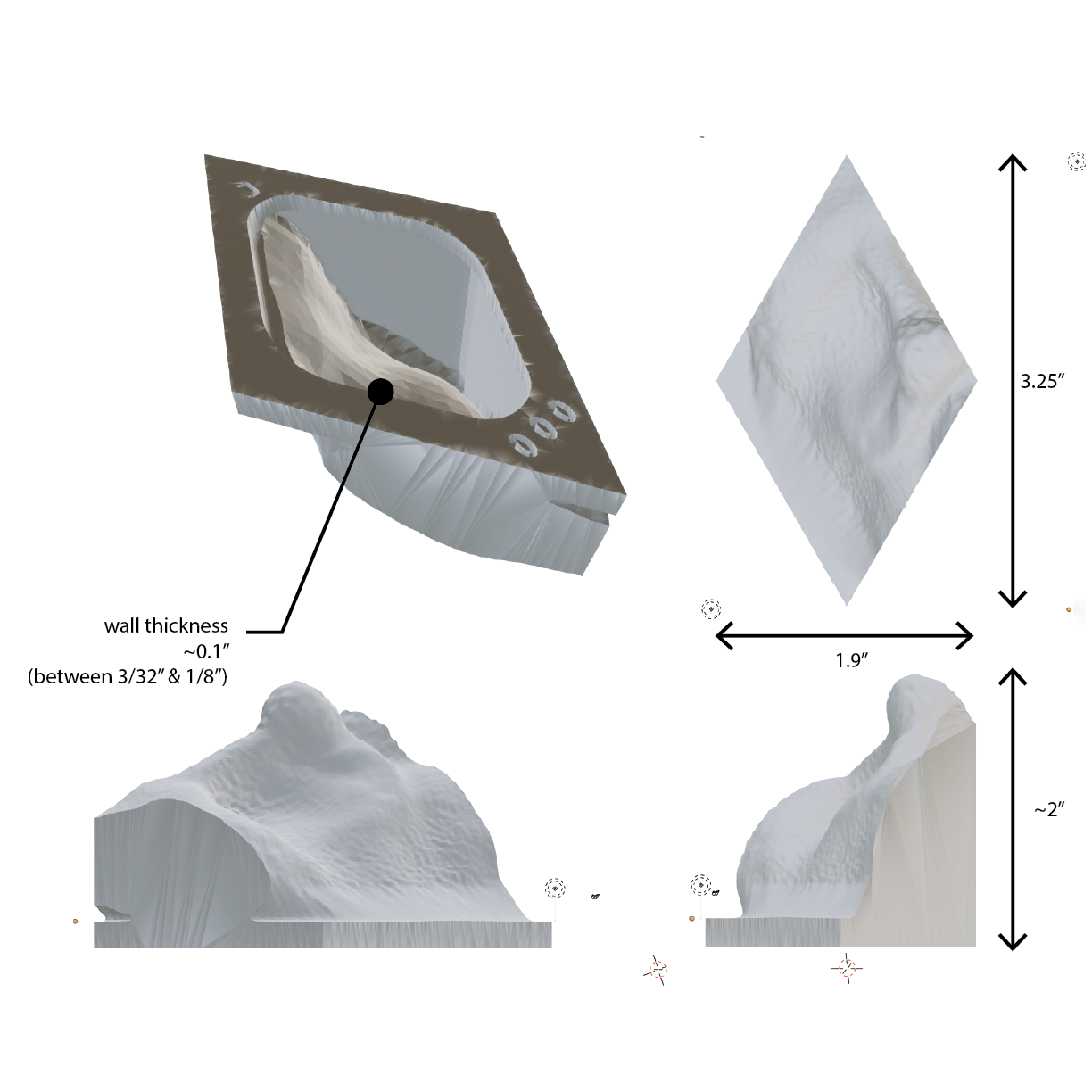
A pipeline is developed for representing 3d polygon meshes as 2d vector displacement maps.
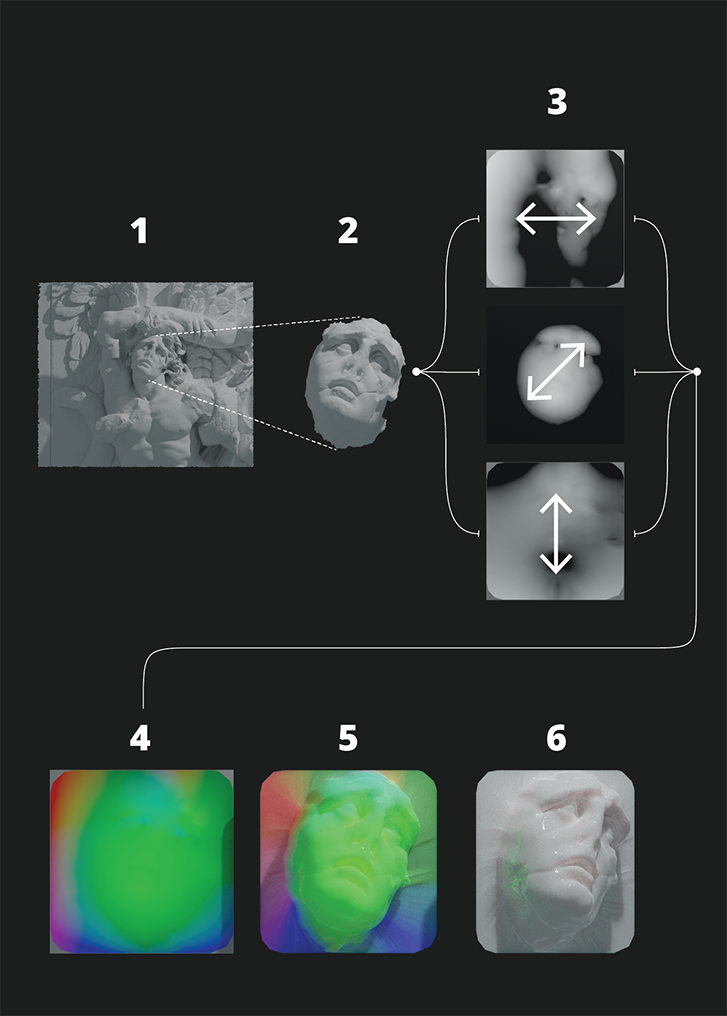
A given 3d model is "squashed" onto a plane, with displacements between points on the plane and locations on the 3d mesh stored as vectors separated into their x,y, and z components. This vector information is stored as the RGB channels of a raster image, which may then be employed to reconstitute the original 3d form.
Having uncovered this format, our team here at UC Berkeley worked tirelessly to develop novel methods for representing 3d polygon meshes as 2d vector displacement maps, and for testing the applicability of existing neural network architectures to this format.
Here's how this works:
A sample form described as a polygon mesh (on the far left) is "squashed" onto a plane, with displacements between points on the plane and locations on the 3d mesh stored as vectors separated into their x,y, and z components. This vector information is stored as the RGB channels of a raster image (the middle image), a format that is both amenable to a GAN, and is able to be later re-interpreted as vector displacements to reproduce similar three-dimensional forms (the image on the right).
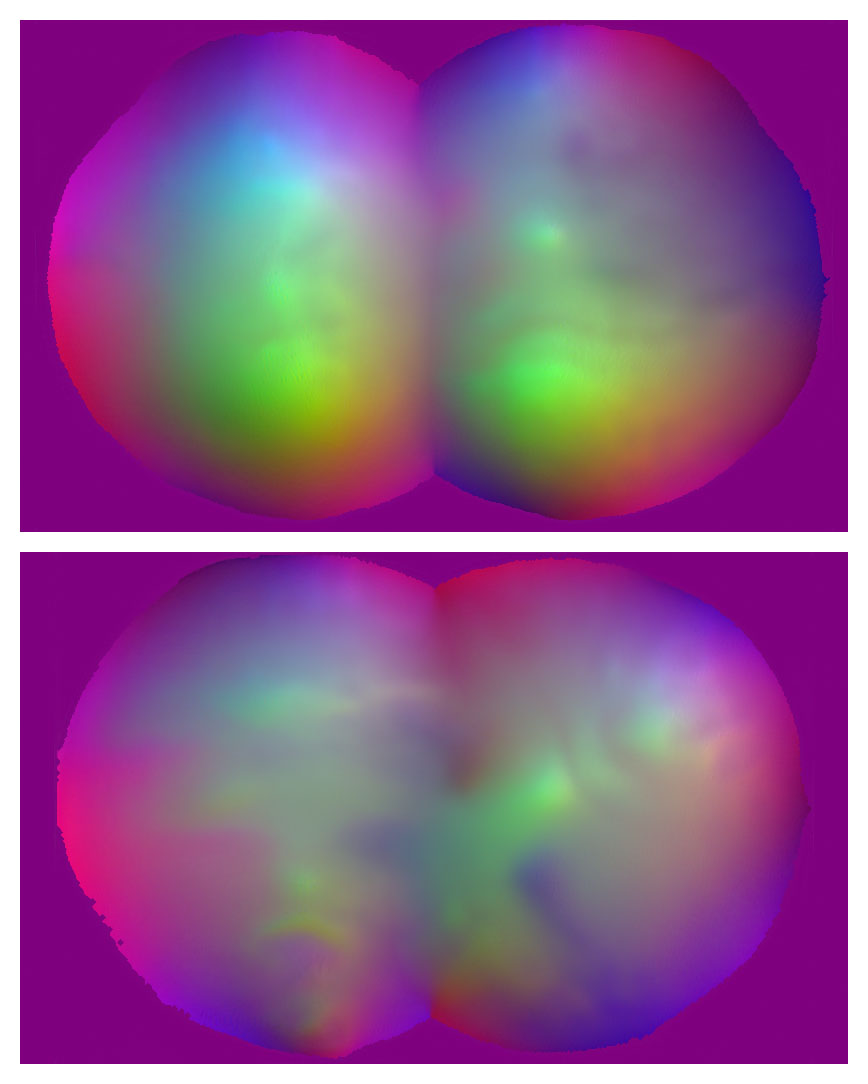
Three vector displacement maps (top) and their corresponding 3d forms (bottom)
The three forms above are *not* generated by a GAN.
Is a GAN capable of capturing the "form language" of vector displacement maps?
We developed methods for applying this process to a constrained family of polygon mesh forms. It is notable that this method cannot describe arbitrary forms - just as in the height-field studies shown previously, there are rules: forms must be "open" on the backside, for example, in order to be "squashed" down onto this plane.
With this pipeline established, and with a sufficiently large dataset of forms in hand, the next question was whether or not a GAN is capable of capturing the "form language" of these test subjects described as vector displacements.
Maybe!?
The first GAN-generated vector displacement map. Kyle Steinfeld, Titus Ebbecke, Georgios Grigoriadis, and David Zhou, 2021
... to which the answer is - maybe!?
The particular "form language" or our test subject makes drawing definitive conclusions a bit difficult. But we were encouraged.
Why were we encouraged by this pulsating pink blob?
Well, two reasons:
First, we can clearly see something resembling the perlin noise surfaces found in our dataset in these synthetic forms. Once again, the vector displacement representation is fairly abstracted away from the 3d geometry on which it was based, but again the GAN learned it anyway. The results have a certain "look" to them, and that's a success.
Second, we felt a small amount of pride to be able to claim that we had made the worlds first (as far as we know) GAN-generated form described as a vector displacement map. This may hold some application in those communities that already use these maps, but we had other plans for more architectural applications.
A Pipeline for Representing 3d Sculptural Relief as Raster Data
Before moving on, a quick summary of the novel pipeline that was developed.
Given a sample form (1), a fragment (2) is selected and "squashed" onto a plane, with displacements between points on the plane and locations on the 3d mesh stored as vectors and encoded into the RGB channels (3) of a raster image (4), which is a format that is both amenable to a GAN, and is able to be re-interpreted as vector displacements (5) to reproduce similar three-dimensional sculptural forms (6).
These synthetic sculptural forms may be combined and aggregated in various ways that are suitable for fabrication (which is exactly what we did).
Artificiale Releivo
Artificial Relief
Kyle Steinfeld, Titus Ebbecke, Georgios Grigoriadis, and David Zhou
2021
Rendered detail of the Artificial Relief pieces. Cast in bronze and produced for display at the Italian Pavilion of the 2021 Venice Architecture Biennale. Kyle Steinfeld, Titus Ebbecke, Georgios Grigoriadis, and David Zhou, 2021
So, that was a pretty technical account. What does it all mean?
The vector displacement pipeline that I just describe is only valuable insofar as it opens up new subjectivities in design practice.
With this in mind, we sought to substantiate that this technique holds some value in the capturing and generating of designs for synthetic architectural relief.
This led us to develop the Artifical Relief project, produced for display at the Italian Pavilion of the 2021 Architecture Biennale.
Here, a dataset of fragmented and decontextualized historical sculptural relief underlies the generation of uncanny forms that straddle the unrecognizable and the familiar.
Given our position on the centrality of data in this kind of creative work, the project requires a reference: an historical piece that functions as a starting point. An object to reconsider. For this, we returned to the ancestor - maybe the great-great-grandfather of those kitchy little sculptural stucco details found all over North Oakland.
(left) North side of the grand staircase of the Pergamon Altar Carole Raddato
(right) Screen recording of a CAD model containing a 3d scan of selected panels from the Pergamon Altar.
We began by drawing sculptural samples from antiquity quite broadly before considering a specific piece in particular, shown here: The Pergamon Altar. This is a Greek construction originating in modern-day Turkey, which was disassembled in the late 19th century, and re-assembled in the early 20th century in a Berlin museum.
Selected sculptural forms into fragments that can be described as deformations of a flat sheet.
The project operates in a manner that mimics the fate of the Pergamon.
It begins with a disassembly of selected sculptural forms into fragments that can be described as deformations of a flat sheet. Where other ML processes often struggle to describe three-dimensional form, our "vector displacement maps" are comprehensible to the machine ...
Selected sculptural forms into fragments that can be described as deformations of a flat sheet.
... and serve to train a neural network to understand the form-language of our selected source material.
Training was slow at first. Results after 48 hours of training left much to be desired.
In comparison to the testing datasets shown earlier, especially those generated using mathematical formulas, the form language for the real-world sculptural forms required by this project appeared to be more difficult for our neural network to learn. Even after more than 48 hours of training, results reamined unsatisfactory.
.
Vector displacement maps can be manipulated and combined using standard raster image editing methods.
As our neural network was busy learning, our team turned its attention to questions about how we would use it.
It turns out that this unique method for describing form carried with it some unique opportunities. Like any other raster data, vector displacement maps can be manipulated and combined using standard image editing methods.
This presented opportunities to combine, aggregate, and merge forms.
An animation of samples drawn from the training dataset.
Of course we should note that, because our model wasn't quite done learning at this point, the forms shown here are combinations of samples from our dataset.
These are not GAN-generated forms.
GAN-Generated forms and related vector displacement maps.
It was around this time that our neural net began to produce some more recognizable results, such as the synthetic form on the right and its corresponding vector displacement map.
This allowed us to apply some of the combinatorial strategies seen in the previous slide. Here, on the left, we see one such application. Two distinct forms are shown, each related to a distinct latent walk. Recognizable features and symmetries appear, only to be disrupted as these twins slide apart, and merge into one another.
A walk through a latent space of GAN-Generated forms
The team also began to think about how to bring these synthetic forms into the world, and considered a variety of options for physical fabrication. Given the classical subject matter, a bronze casting seemed an appropriate possibility.
Around this time we began focusing on processes for translating the synthetic displacement maps into forms amenable to the fabrication processes we had in mind.
Here's how we proceeded.
Two forms directly derived from GAN-generated vector displacement maps.
A "raw" synthetic form - that is, one that is fairly directly derived from the GAN-generated vector displacement map - looks something like this. The single figure represented is fairly clear and well-bounded, and the base plane is clearly discernible.
Because we hoped to break up the reading of the single latent space sample, we processed things a bit further...
Synthetic forms broken up by a simple geometric tiling pattern.
...by breaking up the individual sample into a simple geometric tiling that allowed for easier aggregation. Also at this stage, practicalities such as material thicknesses and labels are accounted for.
A "walk" through the latent space of a GAN trained on Greco-Roman sculptural forms aggregated across a surface in high relief.
An approach to arranging the pieces in aggregate is required, and here again another of our compositional strategies is demonstrated. Recalling the rhythmic symmetry of frieze patterns found in traditional Western ornament, a "walk" through the latent space of a GAN trained on Greco-Roman sculptural forms is aggregated across a surface in high relief.
The Artificiale Releivo installation, as proposed.
Here we see the installation as proposed.
We might term this work a "latent aggregation", which is to say a physical assembly (again, something like a classical frieze) comprised of non-repeating samples from the latent space of our GAN.
The pieces are modular, and while the position of each within the aggregate is fixed, individual orientations are adjusted in order to break down the singularity of the samples, and to encourage multiple simultaneous readings of form.
GAN-generated forms are 3d printed on a standard SLA printer using a filament designed for investment casting.
I'll speak briefly about the fabrication process, and how this piece was realized, which began by printing the GAN-generated forms on a standard SLA printer using a filament designed for investment casting.
48 samples are cast using a lost-wax process.
These prints were then cast in bronze at a foundry about an hour south of Oakland. This scope of work required 48 samples to be cast using a lost-wax process.
Two bronze pieces in a "raw" state, prior to finishing and patina.
Here we see some of the pieces as they arrived from the foundry.
An aggregation of bronze pieces in a "raw" state, prior to finishing and patina.
These are in their "raw" state, prior to finishing, mounting, and patina.
Mounting plates are waterjet cut from brass, and de-burred by hand.
Of course, even in a highly digital process such as what I've described above, there's a great deal of manual work involved in brining a physical piece into the world.
Here we're de-burring a brass mounting plate...
The mounting plates are welded to the back of each piece.
Which is welded on the back of each piece.
A cold patina is applied using a liver of sulfur solution.
Here we see the process of applying a cold patina.
We used a liver of sulfur solution, which results in a fairly dark patina, almost black.
The Artificiale Releivo piece, as installed.
And here we see the final piece as installed.
Outside of the process that I've detailed above, the ambition of this piece is to evoke some suggestion of the historical material from which it is formed - some vestige of the "form language" inherited from the Pergamon alter in particular - while also becoming something quite different. I hope that the piece engages a viewer by hovering at the "uncanny" boundary of individually recognizable forms and a differentated field that suggests the latent space of the GAN.
I'll leave you with these slides showing details of the final piece.
In summary, the project stands as an illustration that:
1. Image-based neural networks do indeed hold application in the generation of synthetic architectural sculptural forms.
2. The dataset is a key point of intervention in a machine-augmented process, and that data is the central material of this new medium.