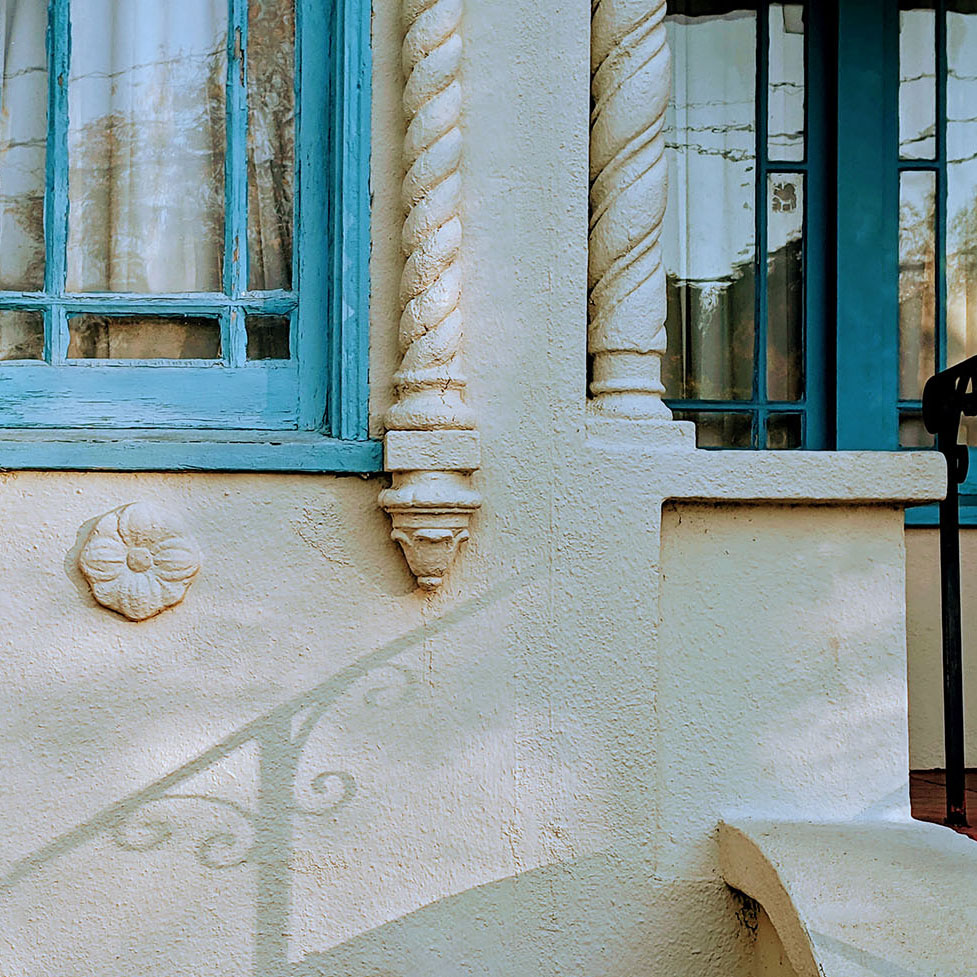A sculptural bronze produced for display at the Italian Pavilion of the 2021 Venice Architecture Biennale.
Kyle Steinfeld, 2021
Ok. One last project.
So, it's one thing to talk about the possible futures of ML in design, and quite another to find applications in the present. To not only ask: "what is the neural net for?", but "what is the neural net for *right now*?"
This last project that I'll talk about today is ongoing, it's in active development, and I'd like to take a bit more time to unpack it because I think it speaks to the current state of things in the application on ML to design.
(left) Synthetic Oakland Kyle Steinfeld, 2018
(right, center) A single-family home in North Oakland Kyle Steinfeld, this morning.
The project began with the start of the pandemic.
The places you see here - this is where I live, this is my neighborhood in Oakland - and this is where I found myself confined in the lockdown of March of 2020. I spent quite a long time taking walks in this neighborhood with my kids, and as we walked - when I wasn't taking questions about The Legend of Zelda - I found myself thinking as I walked about the modest architecture of these buildings that are within walking distance of my home.
In particular, I started thinking about these ornamental elements such as you see here pictured on the right.
In the fever dream of the pandemic, I became obsessed with these little bits of architecture - how they're expressed as these little deformations of stucco that hold imagistic qualities. They can look like flowers or like soft-serve ice-cream. These kitch little pieces of - probably foam covered in plaster - are applied to recall some vague Western tradition - Greek, Roman, Italian, French... it's hard to tell, and it hardly matters.
(left) Entrance to the Carson Pirie Scott Building Louis Sullivan, 1903 Photograph by Hedrich-Blessing, 1960.
In their historicism, they play on our capacity for recognition and recall; In their constructed illusion of high relief, they play on our tendency to perceive three dimensional form. These little optical illusions sprinkled all over my neighborhood began to seem really important: they offer each dwelling something of an identity, and allow us to differentiate one otherwise unremarkable house from another.
Certainly, there's precedent for architects working in this way, as we see here.
It struck me that this modest and easily-overlooked medium of architectural expression is suggestive of a yet-to-be-explored domain of application for the technologies I've been experimenting with.
Certain strains of contemporary architectural form-making hold resonance with certain threads of imagistic pattern-making found in machine-augmented visual art.
One of these pieces operates on pixels, the other on polygons. Can we bring these two together?
Walking the streets of Oakland, it occured to me that certain strains of contemporary architectural form-making hold resonance with certain threads of imagistic pattern-making found in machine-augmented visual art.
It seemed plausible for there to be some resonance here - some way to make existing neural networks instrumental in this domain. To bring existing technologies, most of which are based on raster images such as you see on the right, to bring these to bear on a sort-of generative architectural sculptural ornament.
There is nothing inherent in the existing technology that leads us to raster images. Indeed, there are creative applications of machine learning that span different representations: from text-based models, to graph models, to even some models that operate on 3d boundary representations. However, some of the most well-developed technologies in this space grew out of problems in computer vision, and are built around raster images. And so, a major motivation of this project focuses on a question of representation.
After all the two images we see here appear to hold no important conceptual distinction, rather, the difference appears to me a matter of representation: one operates in pixels in 2d, the other in polygons in 3d. Can we bring these two together?
Can the raster representation that dominates much of the relevant technical foundational work in ML be adapted to describe architectural form in more robust ways?
A double-sided depthmap of a canonical CAD object. Here, the red channel represents a front-facing depthmap while the blue channel represents a back-facing depthmap.
So, with these thoughts in our heads, a team here at UC Berkeley and I got to work.
We sought to understand if the raster representation that dominates much of the relevant technical foundational work in ML could be adapted to describe architectural form in more robust ways.
Since our subject matter concerns architectural sculptural relief, initial experiments examined the illusion of depth in relief.
All hail the king of the forest!
Recalling the "Fresh Eyes" work from 2018, we began by experimenting with variations on a traditional depthmap.
In a "depthmap" (or heightfield) raster data is used to encode the displacement of a plane along a single axis - lighter pixels are displaced more, and darker pixels are displaced less. This format is well-known and is standard in a range of practices; from GIS representations of topography to "bump" mapped materials used in renderings.
As an initial experiment, we wanted to see if we could train a neural net to generate synthetic depthmaps that describe interesting forms.
A variation of a depthmap in which depth information from different directions is encoded into the separate channels of an RGB image.
To up the ante, we developed a "homebrew" variation of a depthmap that encodes depth information from different directions into the separate channels of an RGB image.
While it's a interesting technical question as to if a neural net can capture and reproduce patterns encoded in this way, we were also interested to know if our GAN was able to capture the "form language" of the test subjects shown here.
This, of course, is Squirtle... a Pokemon. On the previous slide was Totoro, king of the forest. I think you can see the form language we were hoping to reproduce.
Synthetic Pokemon figures described by a GAN-generated two-sided depthmap.
... and, as you can see here, we found some modest success!
Shown here is a collection of synthetic pokemon figures. These are not really fully 3d forms (maybe two-and-three-quarter dimensional?), but they are fully 3d printable (I can send you a file if you'd like) because they are produced by a GAN-generated two-sided depthmap.
We see the synthetic depthmap on the left, and a form derived from this map on the right.
Synthetic Pokemon figures described by a GAN-generated two-sided depthmap.
I would claim modest success with this early experiment for two reasons.
First, its clear that the architecture of this existing GAN (this is StyleGAN 2) successfully learned a distinct language of 3d(ish) forms described as raster data. The depthmap representation is somewhat abstracted away from the 3d geometry on which it was based, but the GAN learned it anyway. The results have a Pokemon "look" to them. That's a success.
Further, I find it compelling that a relationship is established here between a descriptive format (the depthmap) and a 3d form (the Pokemon shape) that not only is amenable to being learned by a neural net, but also is suggestive of a fabrication process.
What I mean is that the constraints of a two-sided depthmap map nicely onto certain fabrication constraints related to, say, CNC milling.
It's cool that we could mill one of these shapes quite easily.
Training animation for a 3-channel relief of human figures
With this early success under our belt, the project drifted a bit as we attempted to extend this technique into the more complex scenes and more detailed forms that we felt were necessary to match our ambitions for architectural application.
Synthetic 3-channel relief of human figures
We built a one-sided "layered" variation of a 3-channel depthmap intended to capture human forms and gestures.
meh.
The results were a little "meh".
There were several reasons for this probably... our datasets remained quite small, the artificiality of the subject matter was less than compelling, etc.
Ultimately, I feel we began to encounter the limits of a tradtional depthmap. No matter how many channels we introduced or directions we extruded from, the synthetic forms still felt quite "flat" and "directional" in comparison to those precedents that really inspired us.
If we were to see the project progress, we would need to shift our thinking somehow. We decided to look a little further afield to raster representations that could more robustly describe the forms we were after.
Which is precisely what we found in a bizarre raster representation drawn from an obscure corner of the world of 3d animation.
A vector displacement map applied in the Mudbox CAD software YouTube user mudoglu
What is this bizzare form of raster representation?
Well, it's called a "vector displacement map", and it turns out to be a pretty good way of representing sculptural form in a way that is understandable to a raster-based neural network.
Vector displacement is a relatively obscure approach to digital modeling developed for character design and animation applications.
This format addresses the problem of depicting geometrically detailed sculptural forms in a lightweight and portable way. Rather than relying on 3d geometry for certain details, a 2d raster image is employed. When this image is applied to a 3d surface as an image map, it can describe a "displaced" height and direction relative to this surface.
In a vector displacement map, displacements are stored as vectors of arbitrary length and direction. This vector information is separated into its X,Y, and Z components and is stored as the RGB channels of a full-color raster image.
A simple way of understanding this approach is to refer to its ancestor - the depth map that I discussed earlier. These are sometimes called "height-fields" or "bump maps", and if you've worked with rendering software, you're probably aware of these terms. In this "regular" displacement map, a greyscale image is mapped onto a 3d surface, which is then displaced during the rendering process.
A vector displacement map functions in a similar way, but extends the technique to capture a broader range of forms. Here, displacements are stored not as "pushes" or "pulls" along a single direction, but rather along a vector of arbitrary length and direction. This vector information is separated into its X,Y, and Z components and is stored as the RGB channels of a full-color raster image.
(left) Creature design by Nicolas Swijngedau www.facebook.com/NicolasDesign
Vector displacement maps have found relatively widespread application in the niche practice of 3d character animation, where this same technique has also been used to transfer details from one model to another, and is used as a "stencil" or "stamp" tool in 3d sculpting applications.
(right) A single-family home in North Oakland Kyle Steinfeld, this morning.
To my knowledge, vector displacement maps have not been used in architectural design... but they should!
There seems to be some real resonance between the sculpting interfaces offered by contemporary character modeling software, such as Z-brush shown on the left, and the kitchy stucco deformations that dominate North Oakland.
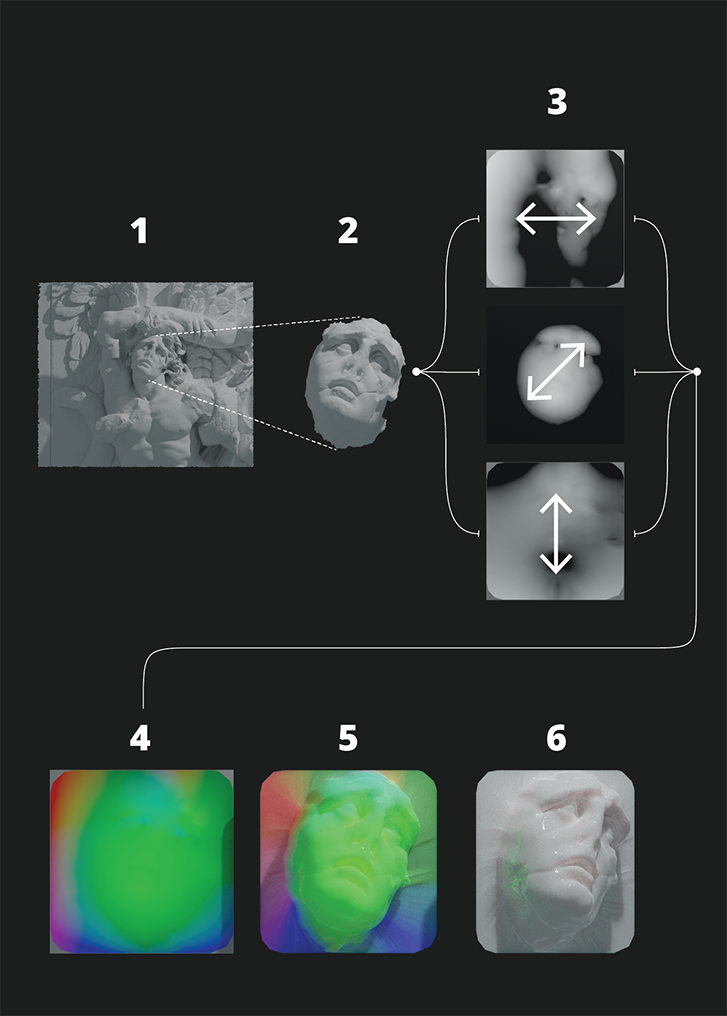
A pipeline is developed for representing 3d polygon meshes as 2d vector displacement maps.
A given 3d model is "squashed" onto a plane, with displacements between points on the plane and locations on the 3d mesh stored as vectors separated into their x,y, and z components. This vector information is stored as the RGB channels of a raster image, which may then be employed to reconstitute the original 3d form.
Having uncovered this format, our team here at UC Berkeley worked tirelessly to develop novel methods for representing 3d polygon meshes as 2d vector displacement maps, and for testing the applicability of existing neural network architectures to this format.
Here's how this works:
A sample form described as a polygon mesh (on the far left) is "squashed" onto a plane, with displacements between points on the plane and locations on the 3d mesh stored as vectors separated into their x,y, and z components. This vector information is stored as the RGB channels of a raster image (the middle image), a format that is both amenable to a GAN, and is able to be later re-interpreted as vector displacements to reproduce similar three-dimensional forms (the image on the right).
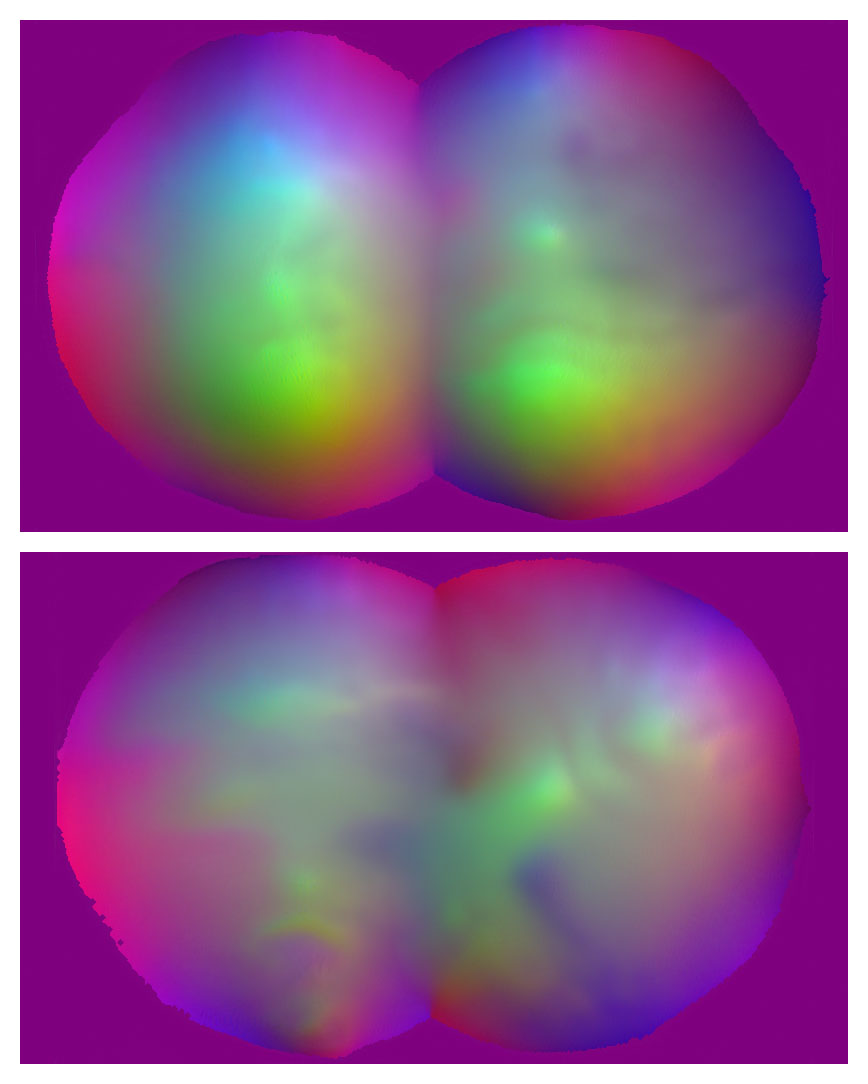
Three vector displacement maps (top) and their corresponding 3d forms (bottom)
The three forms above are *not* generated by a GAN.
Is a GAN capable of capturing the "form language" of vector displacement maps?
We developed methods for applying this process to a constrained family of polygon mesh forms. It is notable that this method cannot describe arbitrary forms - just as in the height-field studies shown previously, there are rules: forms must be "open" on the backside, for example, in order to be "squashed" down onto this plane.
With this pipeline established, and with a sufficiently large dataset of forms in hand, the next question was whether or not a GAN is capable of capturing the "form language" of these test subjects described as vector displacements.
Maybe!?
The first GAN-generated vector displacement map. Kyle Steinfeld, Titus Ebbecke, Georgios Grigoriadis, and David Zhou, 2021
... to which the answer is - maybe!?
The particular "form language" or our test subject makes drawing definitive conclusions a bit difficult. But we were encouraged.
Why were we encouraged by this pulsating pink blob?
Well, two reasons:
First, we can clearly see something resembling the perlin noise surfaces found in our dataset in these synthetic forms. Once again, the vector displacement representation is fairly abstracted away from the 3d geometry on which it was based, but again the GAN learned it anyway. The results have a certain "look" to them, and that's a success.
Second, we felt a small amount of pride to be able to claim that we had made the worlds first (as far as we know) GAN-generated form described as a vector displacement map. This may hold some application in those communities that already use these maps, but we had other plans for more architectural applications.
A Pipeline for Representing 3d Sculptural Relief as Raster Data
Before moving on, a quick summary of the novel pipeline that was developed.
Given a sample form (1), a fragment (2) is selected and "squashed" onto a plane, with displacements between points on the plane and locations on the 3d mesh stored as vectors and encoded into the RGB channels (3) of a raster image (4), which is a format that is both amenable to a GAN, and is able to be re-interpreted as vector displacements (5) to reproduce similar three-dimensional sculptural forms (6).
These synthetic sculptural forms may be combined and aggregated in various ways that are suitable for fabrication (which is exactly what we did).
Artificiale Releivo
Artificial Relief
Kyle Steinfeld, Titus Ebbecke, Georgios Grigoriadis, and David Zhou
2021
Rendered detail of the Artificial Relief pieces. Cast in bronze and produced for display at the Italian Pavilion of the 2021 Venice Architecture Biennale. Kyle Steinfeld, Titus Ebbecke, Georgios Grigoriadis, and David Zhou, 2021
So, that was a pretty technical account. What does it all mean?
The vector displacement pipeline that I just describe is only valuable insofar as it opens up new subjectivities in design practice.
With this in mind, we sought to substantiate that this technique holds some value in the capturing and generating of designs for synthetic architectural relief.
This led us to develop the Artifical Relief project, produced for display at the Italian Pavilion of the 2021 Architecture Biennale.
Here, a dataset of fragmented and decontextualized historical sculptural relief underlies the generation of uncanny forms that straddle the unrecognizable and the familiar.
Given our position on the centrality of data in this kind of creative work, the project requires a reference: an historical piece that functions as a starting point. An object to reconsider. For this, we returned to the ancestor - maybe the great-great-grandfather of those kitchy little sculptural stucco details found all over North Oakland.
(left) North side of the grand staircase of the Pergamon Altar Carole Raddato
(right) Screen recording of a CAD model containing a 3d scan of selected panels from the Pergamon Altar.
We began by drawing sculptural samples from antiquity quite broadly before considering a specific piece in particular, shown here: The Pergamon Altar. This is a Greek construction originating in modern-day Turkey, which was disassembled in the late 19th century, and re-assembled in the early 20th century in a Berlin museum.
Selected sculptural forms into fragments that can be described as deformations of a flat sheet.
The project operates in a manner that mimics the fate of the Pergamon.
It begins with a disassembly of selected sculptural forms into fragments that can be described as deformations of a flat sheet. Where other ML processes often struggle to describe three-dimensional form, our "vector displacement maps" are comprehensible to the machine ...
Selected sculptural forms into fragments that can be described as deformations of a flat sheet.
... and serve to train a neural network to understand the form-language of our selected source material.
Training was slow at first. Results after 48 hours of training left much to be desired.
In comparison to the testing datasets shown earlier, especially those generated using mathematical formulas, the form language for the real-world sculptural forms required by this project appeared to be more difficult for our neural network to learn. Even after more than 48 hours of training, results reamined unsatisfactory.
.
Vector displacement maps can be manipulated and combined using standard raster image editing methods.
As our neural network was busy learning, our team turned its attention to questions about how we would use it.
It turns out that this unique method for describing form carried with it some unique opportunities. Like any other raster data, vector displacement maps can be manipulated and combined using standard image editing methods.
This presented opportunities to combine, aggregate, and merge forms.
An animation of samples drawn from the training dataset.
Of course we should note that, because our model wasn't quite done learning at this point, the forms shown here are combinations of samples from our dataset.
These are not GAN-generated forms.
GAN-Generated forms and related vector displacement maps.
It was around this time that our neural net began to produce some more recognizable results, such as the synthetic form on the right and its corresponding vector displacement map.
This allowed us to apply some of the combinatorial strategies seen in the previous slide. Here, on the left, we see one such application. Two distinct forms are shown, each related to a distinct latent walk. Recognizable features and symmetries appear, only to be disrupted as these twins slide apart, and merge into one another.
A walk through a latent space of GAN-Generated forms
The team also began to think about how to bring these synthetic forms into the world, and considered a variety of options for physical fabrication. Given the classical subject matter, a bronze casting seemed an appropriate possibility.
Around this time we began focusing on processes for translating the synthetic displacement maps into forms amenable to the fabrication processes we had in mind.
Here's how we proceeded.
Two forms directly derived from GAN-generated vector displacement maps.
A "raw" synthetic form - that is, one that is fairly directly derived from the GAN-generated vector displacement map - looks something like this. The single figure represented is fairly clear and well-bounded, and the base plane is clearly discernible.
Because we hoped to break up the reading of the single latent space sample, we processed things a bit further...
Synthetic forms broken up by a simple geometric tiling pattern.
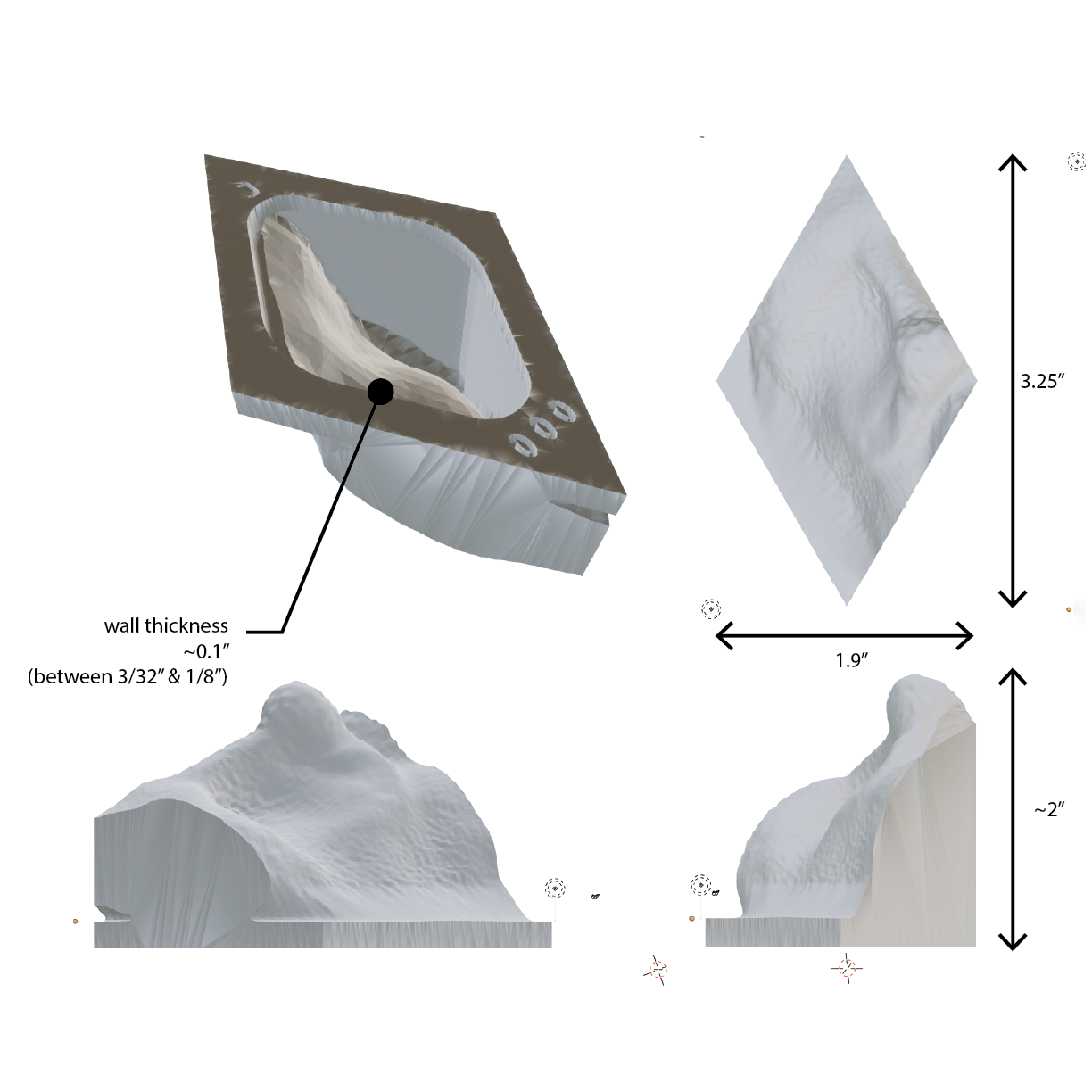
...by breaking up the individual sample into a simple geometric tiling that allowed for easier aggregation. Also at this stage, practicalities such as material thicknesses and labels are accounted for.
A "walk" through the latent space of a GAN trained on Greco-Roman sculptural forms aggregated across a surface in high relief.
An approach to arranging the pieces in aggregate is required, and here again another of our compositional strategies is demonstrated. Recalling the rhythmic symmetry of frieze patterns found in traditional Western ornament, a "walk" through the latent space of a GAN trained on Greco-Roman sculptural forms is aggregated across a surface in high relief.
The Artificiale Releivo installation, as proposed.
Here we see the installation as proposed.
We might term this work a "latent aggregation", which is to say a physical assembly (again, something like a classical frieze) comprised of non-repeating samples from the latent space of our GAN.
The pieces are modular, and while the position of each within the aggregate is fixed, individual orientations are adjusted in order to break down the singularity of the samples, and to encourage multiple simultaneous readings of form.
GAN-generated forms are 3d printed on a standard SLA printer using a filament designed for investment casting.
I'll speak briefly about the fabrication process, and how this piece was realized, which began by printing the GAN-generated forms on a standard SLA printer using a filament designed for investment casting.
48 samples are cast using a lost-wax process.
These prints were then cast in bronze at a foundry about an hour south of Oakland. This scope of work required 48 samples to be cast using a lost-wax process.
Two bronze pieces in a "raw" state, prior to finishing and patina.
Here we see some of the pieces as they arrived from the foundry.
An aggregation of bronze pieces in a "raw" state, prior to finishing and patina.
These are in their "raw" state, prior to finishing, mounting, and patina.
Mounting plates are waterjet cut from brass, and de-burred by hand.
Of course, even in a highly digital process such as what I've described above, there's a great deal of manual work involved in brining a physical piece into the world.
Here we're de-burring a brass mounting plate...
The mounting plates are welded to the back of each piece.
Which is welded on the back of each piece.
A cold patina is applied using a liver of sulfur solution.
Here we see the process of applying a cold patina.
We used a liver of sulfur solution, which results in a fairly dark patina, almost black.
The Artificiale Releivo piece, as installed.
And here we see the final piece as installed.
Outside of the process that I've detailed above, the ambition of this piece is to evoke some suggestion of the historical material from which it is formed - some vestige of the "form language" inherited from the Pergamon alter in particular - while also becoming something quite different. I hope that the piece engages a viewer by hovering at the "uncanny" boundary of individually recognizable forms and a differentated field that suggests the latent space of the GAN.
I'll leave you with these slides showing details of the final piece.
In summary, the project stands as an illustration that:
1. Image-based neural networks do indeed hold application in the generation of synthetic architectural sculptural forms.
2. The dataset is a key point of intervention in a machine-augmented process, and that data is the central material of this new medium.